애니 듀크의 "결정: 흔들리지 않고 마음먹은 대로", 이 책은 포커에서 돈을 거는 베팅(betting)이라는 표현을 빌어 결정(decision)에 대해 설명한다. 저자는 우리의 삶을 좌우하는 요인이 두가지라고 이야기 한다. 그것은 의사 결정의 질과 운이다. 둘의 차이점을 알고 결정에 돈을 거는 것 즉, 베팅하듯 사고하는 것이라고 이야기 한다. 처음에는 와닿지 않을 수 있지만 책을 읽다 보면 이것이 다구나 라고 이해할 수 있을 것이다.
이 책은 예측에서 많이 이야기 하는 야구 경기를 예로 시작한다. 결과적으로는 패한 경기의 감독의 이야기를 하면서 그가 결정한 투수 교체에 대해서 그 결과로 판단하는 이야기를 가장 처음 한다. 그녀는 자신의 포커 커리어에서 경험 많은 선수들에게 배운 결과로 판단하는 것이 얼마나 위험한지 이야기 한다. 그녀는 포커 경기를 하면서 단기적으로 몇번의 패가 좋지 않았다는 이유만으로 전략을 바꾸고 싶은 충동이 들더라도 포커 선배들은 꿋꿋이 그것을 이겨내야 한다고 조언했다.
그녀는 포커에는 불확실성이 존재하기 때문에 결정에 대해 가장 빠르게 배울 수 있는 의외의 장소라고 말한다. 저자는 포커에서 성공하려면 타고난 재능보다, 본인의 의도대로실행하는 방법을 찾는 것이 더 중요하다고 이야기 한다. 흔한 의사결정 함정을 피하고 이성적으로 결과로 부터 교훈을 얻고, 의사결정 과정에서 최대한 감정을 배제하며 전략을 실행해야 한다고 이야기 한다. 이것은 우리가 다른 의사 결정을 할 때에도 마찬가지이다.
의사 결정을 할 때 함정은 여러 곳에 도사리고 있다. 저자는 자신이 다 알고 있다는 위험한 착각을 버려야 한다고 한다. 쉬운 예로 동전을 던져서 나오는 확률은 어떠한가? 50:50이라고 이야기 할 것인가? 이것은 이론적이지만, 우리가 던지려고 하는 동전은 실재로 그 확률을 가지고 있을까? 그러므로, 누군가 아무 동전을 던지고 확률을 묻는다면, 우리는 '확실하지 않다.'라고 이야기해야 맞을 것이다.
우리가 이러한 불확실성을 기꺼이 받아들일 때 더 나은 의사결정자가 될 수 있는 까닭은 여러가지가 있는데 그 중 두가지 있다고 저자는 말한다. 첫 번째는 '확실하지 않다'는 그저 이 세상을 좀 더 정확히 묘사한 말일 뿐이기 때문이다. 두 번째는 확실하지 않다는 걸 받아들이면 흑백논리의 함정에 빠질 가능성이 줄어들기 때문이다.
그리고, 이와 같은 불확실성은 생각보다 자주 발생한는 이변도 포함하고 있다. 예를 들어 선거에서 어떤 후보가 60대 40이나 70대 30의 승률이 전망된다고 해보자. 저자는 이 후보가 질 가능성이 얼마나 높은지(물론 그 반대의 경우도) 뼛속 깊이 알고 있다. 즉, 60%로 이긴다고 예상된다는 이야기는 40%의 확률로 진다는 뜻이라는 것이다. 저자는 이러한 불확실성의에 대해 알고, 틀림에 대해서 다시 정의하고, 자산의 추측이 자원 배분마저 좌우한다는 걸 인정해야 한다고 주장한다.
우리는 생존에 필요한 기술의 경우 1형 오류(긍정 오류)를 저질러 치러야 하는 대가는 2형 오류(부정 오류)의 대가보다 덜했다. 달리 말해, 나중에 후회하는 것보다는 미리 조심하는게 낫다는 것이다. 우리는 직접적으로 경험하는 것들, 특히 우리 목숨이 달린 경우에는 믿음에 관한 대단한 의심을 발동시키지 않았다. 우리는 스스로를 편협하지 않고 새로운 정보에 따라 믿음을 얼마든지 바꿀 수 있는 사람이라고 생각하지만 실재로는 그 반대라는 것이다. 우리는 '새로운 정보에 걸맞게 믿음을 바꾸기'는 커녕 그 정보를 '우리의 믿음에 맞추어 해석'하는 것이다.
그렇다면, 우리가 의사결정을 내릴 때 어떻게 하는 것이 좋을까? 우리의 믿음에 있어서 단순히 자신이 있는지 없는지가 아니라 얼마나 자신이 있는지 생각하는것이 바람직 할 것이다. 이를 색으로 표현한다면 흰색 혹은 검은색 이라기 보다는 중간의 어디인가 있는 회색이 될 것이다.
결정을 하는데 학습은 어떤 역할을 할까? 의사 결정에 대한 실천을 해야 하는 시간에 가까운 피드백이 많이 발생할 때 학습이 일어난다고 한다. 그렇다면, 포커 게임은 아주 이상적인 학습 환경이 될 것이라고 저자는 이야기 한다. 베팅을 하고, 상대로 부터 즉각적인 반응을 얻고, 그 판에서 이기거나 진다. 이야기한 것과 같이 결정에 대한 피드백이 즉각적으로 일어난다.
하지만, 결과를 통해 얻을 수 있는 피드백은 성공과 실패 뿐일 경우가 많다. 그러므로, 그 뒤에 숨어 있는 내용을 다 알 수 없다. 이유는 결과물에서 무엇이 우리의 잘못이고 무엇이 아닌지 알기 쉽지 않다. 앞에서도 이야기했 듯이 결과물의 질에서부터 되짚어가 믿음이나 의사결정의 질을 판가름할 수 없기 때문이다. 달리 말하면, 불확실성이 개입되어 있어 결과가 실력 때문인지 운 때문인지 모르기 때문에 학습속도를 늦추기 때문이라고도 할 수 있다. 그렇다면, 결과보다는 과정에 대해 피드백을 받아야 한다고 볼 수 있다.
그렇다면, 결정을 하기 위해서 우리가 선택지를 만들어 놓고 결정을 내릴 때, 중간값 없이 옳고 그름으로 나눠어야 하는가? 저자는 아니라고 한다. 왜냐하면, 흑백논리가 의도적 합리화와 자기위주편향 모두를 촉진시키기 때문이라고 한다. 이와 다르게 포커에서 베팅하듯 생각해면 대안적인 가설들, 자기위추편향이라는 경로와 반대되는 결론을 뒷받침하는 이유들을 열린 마음으로 탐색할 수 있다고 이야기 한다. 반대되는 생각을 더 자주, 진지하게 탐색하면 진실에 더 가까이 갈 수 있다고 이야기 한다.
또한 같은 목표로 모인 다양한 사람들의 시너지를 얻는 것에 대해서도 이야기 한다. 이는 특정 시각을 일방적/의도적으로 합리화 시도, 편향을 증폭하고, 자신의 믿음을 지키게 만들고, 의사 결정 과정을 왜곡, 집단 순응 사고하게 하는 확증적 사고에서 벗어나게 한다고 한다. 대신에 대안적 시각/가설을 공평하게 개방적으로 고려하고 객관성을 장려한고 편향에 맞서는 논쟁을 받아들이는 탐색적 사고를 돕는다고 주장한다.
그렇다고, 팀을 만든다고 그냥 얻어 지는 것이 아니고, "진실추구 규율의 청사진"을 가져야 한다고 이야기 한다. 이는 다음과 같은 규율을 가져야 한다고 이야기 한다. 1. 그룹 내 진실 추구와 객관성, 열린 마음을 보상하며 정확성에 집중 2. 자신의 의견이 나 주장에 대해 설명할 책임(사전에 고지되어야함) 3. 다양한 생각에 대한 개방성 다시 말해 진실을 추구 하려는 공동의 목표를 가진 그룹의 규율은 개인의 편향에 도전하는 다양한 시각을 독려하고 권장해야 한다고 말한다.
팀이 토론을 할 때, 진 게임에 대해서 보다는 승리한 게임에 대해 이야기하는 것(이기기까지의 과정에서 한 실수를 찾아내야 할지언정)이 덜 고통스럽다. 그렇기 때문에 이러한 새로운 습관을 훈련할 때에 도움이 된다. 애자일에서 회고할 때, 잘하고 있는 부분에 대해서 이야기 하는 것도 이런 맥락이지 않을까?
결정을 할 때, 책임 연습이란 책임 연습이란 우리의 행동이나 믿음에 대해 다른 사람에게 해명할 용의나 의무라고 한다. 투자를 할 때, 손실 한계를 정해 놓고 자기 위주 편향을 피하기 위한 방법도 이와 유사하다고 할 수 있다.를 말한다. 내기는 일종의 책임 연습이다. 계속 이기고 있을 때도 마찬가지이지만, 지고 있는 순간에는 내가 운이 나빠서인지, 실력때문인지 알기 힘들기 때문에 정신을 차리고 우선 멈춰야 한다.
책의 5장에 새로운 결정 기준을 제시하는 사람들들의 이야기를 한다.
첫 번째가 머튼의 공유 주의(공산주의와 혼동하지 말기를)라는 규범을 이야기 하는데, 이는 그룹 내에서 데이터를 공동으로 소유한다는 뜻이다. 공유를 원칙으로 삼아야만 완전하고 열린 의사소통이 가능하다고 주장한다. 데이터와 정보를 공유하는 것은 진실 추구 규범의 다른 요소들처럼 먼저 합의를 필요로 한다. 그리고, 조금이라도 관련될 수 있는 정보는 뭐든 추가하는 식으로 만전을 기해야 한다. 평가할 때에도 필요에 따라 세부적인 내용까지 뽑아내기 위해 서로에게 질문을 던져야 한다.
두 번째의 경우는, 여러분이 싫어하는 그 사람이 때때로 옳은 말도 한다는 것을 인정하라 것이다. 우리는 좋은 아이디어 또는 나쁜 아이디어만 가진 사람은 없다는 사실을 자주 잊곤 한다. 예를 들어 정치판이 양극화되어 있는 상황에서도 진보주의자들은 보수주의 언론을 더 읽고, 보수주의자들 역시 반대 접근도 해야 한다고 이야기 한다.
세 번째는 이해관계가 시야를 흐리지 않도록 주의하라고 이야기 하면서, 무사무욕주의(Disinterestedness 사심이 없음)가 중요하다고 설명한다.
네 번째는 여러 곳에서 이야기 하고 있는 '악마의 변호인'이다. 악마의 변호인은 확실해 보이는 내용에도 반대하는 사람이라고 간단히 말할 수 있따. 이 방법으로 불확실성을 받아들이고 이것을 소통하는 방식에 녹여넣으면 '대립만 일삼는 반대'는 눈 녹듯 사라진다고 이야기 한다. 애초에 '확실하지 않다'는 것 부터 시작하기 때문이라고 말한다.
마지막 6장에서 지금까지 이야기한 결정과 관련된 몇가지 도구에 대해서 이야기 하고 정리한다.
모든 후회하기에 가장 좋은 때는 결정을 내리기 전이다. 이렇게 할 수 있는 도구는 '미래의 자신이 이 결정에 대해 어떻게 생각할 것인가', 아니면 '과거의 자신이 이런 결정을 내렸다면 오늘 우리가 그것에 대해 어떻게 생각할 것인가'를 상상해 보는 것으로 가능하다.
10-10-10 법칙이 좀 더 상세한 방법이다. 여러분의 선택은 10분 후에 어떤 결과를 가져올 것인가? 10개월 후에는? 10년 후에는? 이 일련의 질문으니 책임 연습 대화(진실 추구 그룹에서도 장려한다)가 포함된 정신적 시간여행을 유발한다고 한다.
앞에서도 이야기 했지만, 일단 멈추어야 악순환을 피할 수 있다고 이야기 한다. 저자는 틸트(Tilt)에 대해서 이야기 하는데 나쁜 결과는 감정에 영향을 미칠 수 있고, 이것이 감정적이고 비합리적인 의사결정을 내리게 하며, 이는 더 많은 나쁜 결과를 가져와 향후 계속해서 의사결정 능력에 부정적인 영향을 미칠 수 있다고 이야기 한다.
또하나의 도구로 백캐스팅(backcasting)과 사전부검(pre-morterm)을 이야기 한다. 백캐스팅은 어떤 일에 성공했다고 가정하고 '나는 왜 성공하였는가?'라고 질문해보는 것이다. 즉, 미래의 지도를 그리기 위해 목표에서부터 거꾸로 돌아오는 것을 말한다. 사전부검은 백캐스팅과 상호보완적이다. 사전부검은 부정적인 미래를 상상한다. 긍정적인 공간과 부정적인 공간 모두 갖지 못하면 완성된 그림이라고 하기 어렵다.
필립 테틀록과 댄가드너의 슈퍼 예측은 다른 사람들 보다 예측을 잘 하는 사람들에 대한 이야기이다. 실재로 이런 사람들이 있는가? 있다면 그들은 어떻게 다른가에 대해 이야기 한다.
나도 마찬가지였지만, 이책을 스터디 그룹과 읽기 시작할 때에는 예측에 대해서는 회의적이었다. 즉, 예측이란 틀릴 수 밖에 없다고 생각하였다. 이 책은 이에 대해서 내가 어떤 부분을 제대로 알고 있고, 어떤 부분을 잘 못 생각하고 있었는지 알려 주었다.
저자는 자신을 '낙관적 회의주의자'라고 불러도 좋다고 한다. 이는 예측은 허구라고 하는 사람들과 예측이 가능하다고 하는 사람들 가운데 어디 즈음이라는 이야기일 수 있다.
저자가 연구를 책의 서두에 먼저 이야기 하는 중요한 결론 2가지는 첫째, 예지력은 실제로 있다는 것과 둘 째는 슈퍼예측가들의 성적을 그렇게 좋게 만든 요인이 있다는 사실이다.
이에 대해서 믿고 믿지 않고는 읽는 사람들의 몫일 수도 있지만, 내가 알고 있던 것과의 차이는 생각이나 예측이라는 것에 대한 틀과 그 내용을 받아 들이는 방법도 차이가 많이 난다. 또한 책에서는 이와 관련된 여러가지 내용을 먼저 이야기 한다.
'생각에 관한 생각' 그리고 노벨상 수상자로 유명한 대니얼 카너먼은 사람이 생각하는 방식을 시스템 1과 시스템 2을 나누어 설명한다. 시스템 1은 증거가 많지 않은 상황에서 빨리 결론을 내리도록 만들어진 장치이고, 시스템 2는 우리가 잘 아는 의식적인 사고 영역이라고 한다. 시스템 1에서 일어나는 과정으로 몇십 분의 1초 사이에 자동적으로 빠르고 완벽하게 이루어진다. 그림자를 본다. 털컥! 걸음아 날 살려라 하며 뛴다. 이것이 시스템 1이다. 시스템 2는 우리가 집중하기로 선택한 모든 것으로 구성된다.
일반적으로 시스템 1이 먼저 튀어 나온다. 시스템 1은 배경에서 빠른 속도로 꾸준히 달리고 있다. 하지만, 시스템 2는 그 답을 심문하는 일을 맡는다. 내 답에 대해 누군가 꼬치꼬치 따지고 들어와도 내가 견뎌낼 수 있을까? 증거를 댈 수 있을까?를 생각하는 것이 시스템 2라고 한다. 이 시스템 2가 중요할 수 있다. 하지만 시스템 1은 이 보다 먼저 동작한다. 무언가에 대해서 의심을 하고 시스템 2를 지속적으로 동작 시켜 시스템 1에 이러한 보정이 포함되도록 훈련해야 한다.
저자는 예측과 관련해서 2가지 부류로 나누어 설명한다. 하나는 고슴도치형 하나는 여우형이다. 고슴도치형은 빅 아이디어 전문가로 예측을 할 때 대담하게 90~100%로 예측한다. 이와는 다르게 여우형은 절충적 전문가로 어떤 질문에 대해 60~70%로 예측한다. 각각의 예측에 대해 이 후 평가를 해보면 대부분의 측면에서 이기는 쪽은 늘 여우형이다. 하지만, 여우형은 언론에서 그닥 좋은 대우를 받지 못한다. 우선 여우는 자신감도 없어 보인다. 무엇이 '확실하다'거나 '불가능하다'라고 말하지 않는다. 그리고 '아마'라는 표현을 즐겨 사용한다. 그들의 말은 복잡할 뿐만 아니라 거기엔 '그러나'와 '한편' 같은 어정쩡한 단어가 많이 섞인다. 그러다 보니, 이런 유형의 사람들이 TV에 나온다면 변덕스럽고 줏대가 없으며 불명확하다고 할 것이다.
저자는 예측을 하는 테크닉으로 페르마이징, 외부 관점, 내부관점, 그리고 관점 통합하기를 이야기 한다.
페르마이징은 쉽게 말하면 문제를 좀 더 작은 문제로 나누어 어림짐작하기를 통해 답을 구하는 과정이다. 예를 들어 '시카고에 피아노 조율사가 몇명인가?'라는 질문에 답하기 위해서는 시카고의 대략적인 인구수, 그리고 평균 가족 구성 인원, 가구당 피아노 보유율, 그리고 대략적인 피아노 조율 빈도를 추정하여 총 필요한 조율량을 추측할 수 있다. 그런 후, 피아노 조율사의 한대 조율 시간과 처리 가능한 업뮤량의 추정을 통해서 필요로 하는 대략적인 피아노 조율사의 수를 예측하는 것이다. 이러한 방식으로 주어진 문제에 대해서 예측을 할 수 있다.
책에서는 누구나 따라 할 수 있는 수퍼 예측가들이 예측에 접근하는 방식에 대해 설명한다. 간단히 말하면 외부 관점에 내부관점으로 조정하여 종합적으로 예측을 하는 것이라고 한다. 이를 위해서 문제를 성분에 따라 풀어헤친다. 아는 것과 모르는 것을 철저히 구분하고, 가정을 조사하는 것이다. 우선 외부 관점의 측면, 즉 비교론적인 관점에서 보면서, 문제의 고유성보다는 그것을 더 넓은 범위의 특수 사례로 취급하여 예측을 수행한다. 그리고, 내부 관점, 즉 문제의 고유성을 부각시킨다. 나의 견해와 다른 사람의 견해의 유사성과 차이점을 확인한다. 이 것은 대중의 지혜를 뽑아내는 여러가지 방법에 주목해야 한다. 책에서는 잠자리의 눈에 비유를 하며, 이 모든 다양한 견해를 예리한 단일 시야로 통합하는 과정이 필요하다고 이야기한다.
마지막으로, 아주 세분화된 확률을 사용하여 판단을 가능한 정확하게 표현한다. 책에서는 예측은 정반합의 과정이라고 말하면서 활용 가능한 정보의 변화에 맞춰 계속 업데이트 해야하는 한시적인 판단이라고 말한다. 저자는 외부 관점과 내부 관점을 종합하는 것이 끝이 아니라, 좋은 출발일 뿐이라 한다. 마치, 우리가 애자일 프로세스를 통해서 업무를 수행하듯 반복적(Iterative)하게 수퍼 예측가는 자신만의 견해를 도출하기 위해 종합할 수 있는 다른 견해들을 끊임없이 찾아 필요에 따라 예측을 수정한다. 그렇기 때문에, 수퍼 에측가들은 신념을 사수해야 할 보물이라기 보다는 검증해야 하는 가설로 다룬다.
영화 '빅 쇼트'는 리먼 브라더스 파산으로 시작했던 경제 위기를 배경으로 한 영화이다. 여기서도 헷지펀드의 퀀트(Quant 정량적 분석 Quantative Analysis을 수행하는 사람)가 나온다. 책에서는 이렇듯 수학을 잘하는 사람들이 더 예측을 잘하는가에 대한 질문도 던진다. 저자는 일부러 예측에는 수학이 그리 필요하지 않다고 이야기 한다. 그래도 예측에 대해서 간단히 수학적인 의미는 파악해 보자. 예측에 대한 확률은 크게 나누면 3가지 설정이 있다고 할 수 있다. 바로, 멘탈 디이얼을 '얼아난다' '일어나지 않는다' 그리고 '아마도'로 설정하는 것`이다. 이러한 언어로 표현되는 어떤 예측에 대해서 틀렸다고 단정해서는 안된다. 예를 들어 '어떤 일이 일어날 확률이 74%'라는 말은 '그렇지 않을 확률이 26%'라는 의미도 되기 때문이다. 이렇게 예측하는 사람들은 확률을 말하라고 할 때 50%를 훨씬 더 많이 사용한다. 그 때 50%는 '아마도'를 의미한다. 50%를 너무 자주 사용하는 사람의 예측은 정확하지 않다고 봐도 큰 무리가 없다.
저자는 슈퍼 예측에 필요한 개인적인 역량으로서 성장 마인드 세트(Growth Mindset)을 이야기 한다. 심리학자인 캐롤 드웩은 '성장 마인드세트를 가진 사람은 자신의 능력을 노력의 산물'이라고 하고 그 노력 만큼 '성장'시킬 수 있다고 한다. 대부분의 사람들은 소위 '고정적 마인드세트(Fixed Mindset)'를 가지고 있다. 고정적 마인드세트를 가진 사람은 생긴대로 사는 것이라고 믿는다. 그들은 능력은 만들어지거나 개발되는 것이 아니라 드러나는 것일 뿐이라고 주장한다. 이것을 예측과 연결해서 생각해 보면, 성장 마인드 세트를 가진 예측가들은 새로운 아이디어를 끊임없이 수집했고 필요하면 서슴지 않고 생각을 바꾼다. 그들은 이렇게 하는데 망설치지 않고, 실수를 당당히 인정하고 새로운 생각을 받아들이는 것을 자랑스러게 생각한다. 즉, 실패는 실수를 확인하고 새로운 대안을 찾아내 다시 시도하는 학습의 기회였다. 이렇게하면, 시행 횟수가 많아지면 착오가 줄고 기술은 세련되어진다. 어떤 일에 능숙해 지는 비결은 비행기나 아주 어려운 기술을 배우는데 필요한 것과 마찬가지로 실제로 그일을 하면서 보내는 시간의 양이 결정한다. 그러나 무작정 하는 연습으로 항상 실력이 향상되는 것은 아니다. 연습을 해도 조심할 부분을 알고 정보를 바탕으로 어떤 연습이 가장 좋은 것인지 알고 연습해야 한다. 이 밖에도 효율적인 연습은 분명하고도 시의적절한 피드백과 함께 해야 한다. 실패를 통해 배우려면 언제 실패하는지 알아야 한다. 실패했다는 것을 알면 무엇이 잘못되었는지 생각하고 수정하여 다시 시도해야 하는 것이다.
팀으로서의 슈퍼 예측 집단은 현명할 수도 있고, 무모할수도 있으며, 둘다일수도 있다. 즉, 집단은 어떤 구성원들 이더라도 하기 나름이다라는 것이다. 저자들이 발견한 잘 동작하는 슈퍼팀은 극단적인 집단사고와 온라인 논쟁의 폐해를 피했다. 무엇보다 다음과 같은 규칙을 잘 지켰다고 한다.
서로에 대한 예의를 잃지 않으면서도
상대방에 대해 비판을 제기하고 무지를 인정하고
도움을 요청하는 분위기를 조성하는 그들만의 문화가 큰 위력을 발휘했다.
나도 다음과 같이 "팀은 단순히 부분의 합이 아니다. 집단이 집합적으로 생각하는 방법은 집단 그 자체의 발현적(emergent) 속성으로, 각 멤버 내부의 사고 과정일뿐 아니라, 멤버들간의 의사소통 패턴의 속성이다."에 동의한다.
그렇다면, 슈퍼 예측가들의 리더는 어떠해야 할까? 책에서는 히틀러가 지배하던 시대의 유명한 장군인 헬무트 폰 몰트케 이야기를 한다. 암울했던 시기의 인물이기 때문에 그 사람에게서 무엇을 배울 것이 있는가 의심할 수 있다. 책의 저자도 그 부분에 대해서 조심 스러운이 있다. 몰트케의 유산이라 이르면서 그가 한말을 인용한다. "전쟁에서는 모든 것이 불확실하다.", "무엇보다 중요한 것은 자신의 계획을 무조건 신뢰해서는 안 된다는 점이었다.", "적의 주력 부대와 처음 마주치는 순간 효력이 계속 확실하게 유지되는 작전은 없다."와 같은 말이다. 여기서 반전은 나도 계속 좋아하는 인용인 "계획대로 승리한 전투는 없지만,계획없이 승리한 전투도 없다"를 이야기한 아이젠하워가 독일의 군 통수권자보다 몰트케의 철학을 더 확실하게 이해하고 있었다고 저자는 이야기 한다. 이러한 철학도 슈퍼 예측팀을 이끄는 리더들 즉, 여러 슈퍼 예측가들의 종합한다는 입장에서는 이와 같이 불확실한 부분을 이야기하는 것일 수 있다는 것이다.
저자는 "결정, 흔들리지 않고 마음먹은 대로"의 애니 듀크가 말하는 특이한 형태의 겸손에 대해서도 이야기 한다. 프로 포커 플레이어 였던 그녀는 자신감 뒤에는 늘 위험이 도사리고 있다는 것을 잘 알고 있었다. 그녀는 게임에 임했을 때 겸손은 적을 앞에 두었을 때의 겸손과는 전혀 다르다고 이야기 한다. 포커 테이블에 앉으면 누구와도 해볼 만하다는 자신감을 갖지만, 그렇다고 해서 내가 게임의 원리를 완전히 터득하고 있다는 말은 아니라고 이야기 한다.
저자는 슈퍼 예측가가 되기 위해 추가적으로 몇가지 알아 두어야 할 사항에 대해서도 이야기한다. 첫 번째는 대니얼 카너먼의 시스템 2의 교정을 시스템 1으로 가져오는 것이다. 사람들은 원래 빠르고 무의식적인 시스템 1이 만드는 실수를 찾아 내기 위해 의식적인 시스템 2를 반성적으로 사용할 수 있다. 예측을 아주 잘하는 사람들도 어쩔 수 없이 편하고 직관적인 사고 모드에 빠지고마는 것이다. 시스템 2를 소홀히 한 탓이다. 일부 슈퍼 예측가들은 시스템 2의 교정에 아주 능숙하며, 가령 물러서서 외부 관점을 받아들이는 행동이 아예 습관화되어 있는 것으로 보인다고 한다. 사실 이런 과정은 아예 시스템1의 일부로 편입되어 있는 경우도 있다고 한다.
그리고, 잘못된 이분법을 버리는 것이다. 나심 탈레브가 이야기 했던 블랙스완이라고 불린 사건이 있다. 실재로 검은색 백조들은 완전히 검은 색이 아니고, 회색이라고 한다. 흰색이라고 믿었기 때문에 회색을 검은색이라고 이야기 하는 것이다. 즉, 블랙 스완이라고 불리는 사건들은 그 조짐이 있었다는 것이다. 앞에서 이야기 했던 리먼 브라더스 파산의 경우도 빅 쇼트에서 이를 예측하고 확인하는 과정에서 보이듯이 갑작스럽게 발생한 것이 아니고 그 조짐이 시장에서 보이고 있었다는 것이다. 그렇기 때문에 빗나갈 예측에 대한 계획을 세울 필요가 있다. 앞에서 이야기한 아이젠하워의 명언과 같이 "계획은 아무 소용이 없다. 그래도 계획은 반드시 필요하다"를 다시 한번 생각해 보고 이에 대해 대비가 필요할 수 있다.
앞에서 이야기 했듯이 나도 예측에 대해서는 매우 부정적이었다. 복권에 대해서도 그렇게 생각하여 필요없는 것이라 생각했다. 하지만, 이 책은 이를 바라 보는 나의 자세를 바꾸는 계기가 되었다. 책에서 이야기 했듯이 예측이 가능한 좋은 질문을 선별하고 (10년후 예측 같은건 불가능하다.), 알수있는 부분과 알수 없는 부분으로 분해하여 가정을 검토 후 추측해 보자. 습관적으로 외부 관점에서 질문을 제기하자. 그리고 나서 내부 관점을 고려하자. 업데이트는 귀찮지만 장기적으로 유익하다. 잡음속에서 미묘한 신호를 골라내고, 자신의 은근한 희망이 스며들지 않도록 경계하자. 정반합, 잠자리의 눈을 가지고 모든 견해를 하나의 이미지로 만들자. 불확실성의 정도를 더욱 자세히 구분하자. 실패/성공 후에 반드시 회고를 하자. 성공에 대해 관신하면 안되고 실패로부터 교훈 찾자. 질문을 하고, 건설적인 대립하자. 직접 예측하고, 피드백을 통해 앞으로 잘 가는지 확인하자.
기존의 연구자들은 센스메이킹을 조금씩 다르게 정의하고 있다. 센스메이킹이라는 용어를 처음 만들어낸 칼 웨익은 조직내에 진행되는 '여러 현상'을 '메이크 센스하게 하는 것(Making of sense)'이라고 하고, 워터맨(Waterman)에 의하면 '모르는 것을 구조화'하는 과정으로, 링과 랜즈(Ring and Rands) '개인들이 그들이 처한 환경에 대한 인지적 지도를 개발화는 과정'이라 정의한다. 경영측면에서의 센스메이킹은 '조직의 내/외부에서 진행되는 불확실하고 복잡한 상황을 명백하게 이해하게 하고 그 이해에 바탕을 둔 행동을 취하게 하는 인지 과정'으로 정의한다. 책[1]에서는 영화 본 아이덴티티에서 주인공의 상황자각력을 예로 들면서, 센스메이킹은 상황자각력이 모여서 이루어지는 것이라 하고 있다.
책에서는 센스메이킹 원칙을 5가지로 설명하고 있다.
원칙 1 현재진행형(ongoing)은 상황에 의미를 부여하고 진행되는 상황을 보아야 한다는 것을 의미한다. 상황을 정지된 사진, 스냅샷으로 보는 것을 의미 하지 않고, 현재진행형(ongoing)인 현실(reality), 과거-현재-미래로 이어지는 맥락을 본다는 것을 의미한다. 원칙 2는 센스메이킹은 회고(retrospective)의 과정이라는 것이다. 회고를 통해 일어난 상황을 돌아 보며 질서(order)를 부여하고자 노력하는 것이다. 원칙 3은 주어진 상황을 이해하기 위해 정당화(justification)가 필요하다는 것이다. 사람들은 주어진 상황이 '합리적'으로 보이게끔(make situations rationally accountable)노력한다. 즉 '내가 경험하고 있는 사건'이 '말이 되는 사건'이라고 스스로를 설득시키고 그 사건의 발생 자체를 이해하려고 노력한다. 그 과정에서 필요한 것은 '정당화'이다. 원칙 4 추정(presumption)은 미루어 생각하여 결정하는 것을 의미한다. 현실을 해석(interpretation)하는 과정 우리가 가지고 있는 잘못된 추정들이 올바른 해석을 방해/제약하여 잘못된 결과를 가져올 수도 있다고 이야기 한다. 원칙 5은 100%의 정확성(accuracy)이 아니라 그럴듯함(plausibility)에 대한 것이다. 넓은 현실(wider reality: 실제 사건이 일어나는 현실세계를 말한다)'에 대한 이미지를 만들어 낸다. 이것은 '비교적 정확하다고 생각하는 현실'이다. 여기서는 '정확성 보다는 그럴듯함'을 추구한다는 것으로 '그럴듯한 추론(plausible reasoning)' 귀추법(Abductive reasoning)이라고 한다. 이 원칙들을 정리해 보면, 센스 메이킹이란 상황을 돌아 보면서 단편적으로 보지 않지만 가장 근접한 답을 찾는 것이고, 실패의 가능성은 당연히 존재하는 것을 인정한다. 실패의 경우, 재빠르게 궤도를 수정하여 파국을 모면하는 것으로 반복적(Iterative)으로 돌아보며(retrospective) 그럴듯한 결론(plausible conclusion)을 내고 행동(action)한다.
책에서는 센스메이킹을 다양한 사례를 들면서 설명한다. 맨 협곡의 참극, 임진왜란이 그 예이다. 특히, 임진왜란은 나심 탈레브의 '블랙 스완'에 해당한다고 설명한다. 챌린저 호 폭발 사건, 항공 모함, 탑건 프로그램에서의 사후 강평에 대해서도 이야기 한다. 특히, 항공 모함이나 사후 강평은 구성원 간의 상호작용 측면에서 매우 흥미로왔다.
기업에서 센스메이킹을 키우는 방법에 대해서도 제언을 하는데, 7가지 포인트를 이야기 한다.
1. '한군데에서의 정보에만 의존하지 마라'라고 이야기 한다. '신호와 소음' 작가인 네이트 실버의 표현에 따르면 혼합방식(hybrid approach)으로 정보를 모아 작성된다. 야구의 경우, 즉 통계자료만이 아닌 스카우트들이 선수를 직접만나고 작성한 리포트 등이 포함된 1차 자료와, 순전히 통계자료로만 구성된 2차 자료를 혼합해 사용하는 것이다. 이 부분은 TV 드라마 '스토브 리그'가 생각나는 부분이다.
2. 현장의 목소리를 들어라 디자인 싱킹으로 유명한 아이디오는 병원의 응급실 디자인을 진행할 때 공간의 동선 관련 질문을 위한 인터뷰에서 다양한 이해 관자자들과 했다. 하지만, 간과한 이해 관계자가 있었으니 바로 환자였다. 만일 '응급실에서의 환자의 경험'이라는 생생한 1차 자료가 없는 상태의 응급실 디자인은 중요한 사용자를 간과한 수준 이하의 디자인이 되었을 것이다.
3. 효율적인 센스메이킹을 위해서 조직 내에서만 통용되는 암호가 필요할 수도 있다. 웨익과 로버츠의 항공모함 연구에서 나오는 컬렉티브 마인드(Collective Mind)를 가진 조직에서는 구성원이 자신의 일을 하면서 자신의 일이 그 사회 시스템 내에서 어떤 역할을 하는 지 확실히 인지(representation)하고, 자신의 행동을 그 시스템의 일부로 연결할 수 있어야 한다고 지적한다.
4. 공감능력을 통한 팀워크를 키워라 여러 다른 책에서도 언급된 픽사의 브레인트러스트 회의는 영화 '토이 스토리' 제작 과정에서 자연스럽게 생겨난 후 사용되고 있다고 한다. 간단히 이야기 하면 여러 직원들을 한 방에 모아놓고 서로 솔직하게 의견을 애기하도록 장려하는 것이다. 모든 참가자는 공평한 기회를 갖되 경영진이 감독을 뜻을 뒤엎을 수는 없다. 이 때 발언자들은 계급을 내려 놓고 이야기 하며 스토리에 대한 이해를 전제로 어떤 모진 발언도 가능하지만, 감정적인 비난은 금지 한다. 이러한 부분은 사후강평(AAR)과 일맥 상통한다.
5. 회의나 사후강평 장소의 크기와 레이아웃도 중요하다. 상명하복의 조직에서 누가 리더의 심기를 거슬리는 보고를 하려하겠는가? 이런 경우 리더가 센스메이킹을 잘못하게 되면 해당 조직은 잘못된 방향으로 나아갈 확률이 크다. 그렇기 때문에, 수평적이고 자유로운 의사소통은 센스메이킹의 첫걸음이라고 이야기 한다. 이 부분은 구글의 아리스토텔레스 프로젝트에서 언급된 우수한 팀의 조건 중 가장 중요하다고 이야기된 심리적 안전과 연결된다. 즉, 내가 무슨 말을 해도 괜찮은 분위기가 형성이 되어야 한다.
6. 반드시 '악마의 변호인'을 두라: 이스라엘의 대실수(Mehdal) 월드워 Z에서 좀비를 대비할 수 있었던 모사드의 10번째 사람이 있다. 9명이 같은 의견을 내더라도 1명은 반대 의견을 내는 시스템이라 할 수 있다. 이와 같은 악마의 변호인(Devil's Advocate)이 있다고 해서 그것이 모든 예상치 못한 참사를 미연에 방지하는 것은 절대 아니다. 조직이 갖고 있는 자원과 시간의 제약 때문에, 모든 위험 요소를 고려해 업무를 처리하거나 전략을 짜는 것은 현실적으로 불가능하다. 그러나 악마의 변호인이 제기한, '만에 하나 일어날 수 있는 사건'이 발생할 때, 그런 제도가 있는 조직과 없는 조직의 대처는 하늘과 땅 차이일 것이다.
7. 흩어져 있는 점들을 연결하라 결국 기업의 능력은 흩어진 점들을 연결하여 지식의 활용을 잘 하는 데 있다는 것인데 여기서의 지식은 꼭 조직 내의 지식 만을 의미하지는 않는다. 조직 외부에 존재하는 지식이나 자원의 활용도 기업에게는 매우 중요하다. MS의 QDOS 사례, 애플의 도시바 HDD건을 사례로 이야기 한다.
개인의 센스메이킹 높이기에 대해서는 다음과 같이 제언한다.
1. 꾸준히 신문 읽기 저자는 뉴스가 '현재의 세상이 어떻게 돌아가는지'를 아는데 가장 효율적인 수단이라고 주장한다. 하지만, 팩트와 주장과 의견을 구분해야 하고 꾸준히 많은 내용을 읽는 것이 중요하다고 한다.
2. 뱅뱅이론에서 벗어나기 저자는 뱅뱅이론을 자신이 위치하고 있는 진영의 논리에 파묻혀 놓치는 부분을 지적하는데 사용한다. 이를 극복하기 위해 사실 파악을 위해서는 여러 진영의 글을 읽는 것이 필요하다는 의견이다.
3. 100% 정확성(accuracy)보다 그럴듯함(plausibility 또는 probabilistically)을 쫓기 여기서는 '슈퍼 예측'에 나온 인간의 2가지 부류를 이야기 한다. 고슴도치형 인간은 모든 것을 하나의 렌즈로 보는 사람들, 즉 일원적인 사람들이라고, 반면 여우형 인간은 다원주의자이자 여러 개의 렌즈로 사물을 보는 사람들이라고 한다. 예측에 관련해서는 이 신중파들은 성실하고, 셍사한 정보를 모았으며, 자기와 다른 시각에 대해 개방적이었고, 지속적으로 정보를 업데이트하는 노력을 보였고, 자신의 접근이 틀렸다고 생각하였을 때 방향을 바꾸는 것에 망설임이 없었다. 즉, 그럴 가능성이 높은(probabilistically) 것에 배팅하는 사람들이었고 이야기 한다.
4. 페르마이징(fermizing)하기: 시카고 피아노 조율사 수 때로는 확률과 어림짐작 계산을 통한 분석능력도 필요하다고 이야기 한다. 시카고에 피아노 조율사를 예측하는 문제에 접근 하는 방법으로 문제를 좀 더 작은 문제로 나누어 어림짐작하기를 통해 답을 구하는 과정을 페르마이징이라고 한다.
5. 집단 지성을 적극적으로 활용하기 팀으로 일하는 것의 장점은 많은 이들이 알고 있다. 하지만 이를 위해 대인 관계 능력이나 감성 지능도 중요하다.
저자는 책을 마무리 하면서, 마크 트웨인의 이야기를 언급한다. '역사는 똑같이 되풀이 되지는 않지만, 그 라임은 맞는다(History Does Not Repeat Itself, But It does Rhyme).' 그러면서, 다른 기업의 사례연구를 통한 학습이나 벤치마킹이 의미있다고 주장한다. 또한 이러한 밴치마킹의 사례의 선정의 경우, 회사의 상황에 따라 선택하는 것을 제안한다. 즉, 중년 이상의 오래된 기업은 꾸준한 개선을 통해서 여전히 잘하고 있는 타 기업 사례가 훨씬 유용할 것이라고 주장하기도 한다
크리스티안 마두스베르그의 '센스 메이킹'은 자신의 책에서 매우 인문학적인 전문가 입장에서 센스 메이킹을 다루고 있다. 책에서는 '인문학적 기초에서 실용적 지혜를 얻는 방식'이라는 정의를 사용한다. 수치나 데이터에서 얻는 알고리즘식 사고와 정반대라고 주장한다. 저자는 센스 메이킹을 통해서 얻은 데이터를 인류학자인 킬리퍼트 기어츠(Clifford Geertz)의 '민족지학(ethonography)'적 현장 조사의 '심층적 기술(thick description)'을 참고하여 '심층적 데이터'라고 불렀다. 40그램의 사과와 1그램의 꿀은 피상적 데이터이지만, 꿀에 절인 사과를 곁들인 로쉬 하샤나Rosh Hashanah(유대인의 명절 중 하나)' 음식은 심층적 데이터라는 것이다.
마두스베르그는 통찰을 얻고 싶을 때에는 맥락을 파고 들어 세계에 완전히 몰입해야 한다고 한다. 이를 통해 피상적 데이터와 심층적 데이터와 관계를 살필 것을 이야기 한다. 이 심층적인 데이터를 알아 내기 위해 마두스베르그는 다음과 같이 지식의 종류를 나누어 설명한다. 이것은 객관적 지식, 주관적 지식, 공유적 지식 그리고 감각적 지식이다. 감각적 지식은 몸에서 기인한다고 했은데 이것은 저차원적으로 이해하고 살아가는 양상을 말해 준다고 한다. 이라크에 파견된 경험 많은 군인들이 근처에 설치된 부비트랩을 모으로 '느끼는' 것이 그것의 예라고 한다.
저자는 센스 메이킹에 귀추법이 필요하다고 이야기 하고 있지만, 디자인 싱킹에 대해서는 비판적인 입장을 가지고 있다. 무엇보다도 사회적 맥락 없이 프로세스 상으로 접근하는 디자인 싱킹은 사실을 오도한고 다양한 관점에서 아이디어를 찾아 내지만 사회적 맥락에 대한 지식없이 공감을 얻을 수 없다고 한다. 또한, 디자인 싱킹이 사람들과 그들이 속한 환경을 관찰하지만 이것을 주마간산식(drive-by) 인류학이라고 비판한다.
마두스베르그의 센스메이킹은 전문가가 되는 것을 방향으로 삼는 것으로 보인다. 여러 사례가 있지만 30년 동안 와인을 만드는 전문가의 이야기가 대표적이다. 유행에 뒤처지면서도 끈기를 가지고 알고리즘이나 화학으로는 알아 낼 수 없는 그의 방식을 이야기 한다.
여기서 주장하는 센스 메이킹이 심층적 데이터를 뽑아 내기 위해서 전문가가 되어야 한다고 주장하는 것으로 보인다. 하지만, 이 내용은 대니얼 카너먼과 게리 클라인이 이야기 한 것과 같이 전문가도 틀릴 수 있다는 부분을 생각해 보자. 이처럼 책에서 이야기 하는 많은 센스 메이킹의 사례도 조금 다른 상황에서는 틀릴 수 있는 것이다.
그렇다면, 우리는 어떻게 센스 메이킹을 해야 하는 것일까? 책의 내용만큼이나 어려운 질문이다.
클린 아키텍처[1]의 5부 아키텍처에서는 원칙이라고 분류하여 설명하지는 않는다. 물론 YAGNI(You Aren't Going to Need It), KISS(Keep It Simple Stupid), DRY(Don't Repeat Yourself)에 대해서 언급하기는 하지만 이 원칙은 아키텍처 설계와 관련되지만 객체 지향 설계에서도 채용되는 개념으로 클린 아키텍처에서 말하는 아키텍처 설계의 핵심 원칙이라고 하기는 어렵다. 여기서는 클린 아키텍처 책의 4부에서는 이야기 하는 주요 개념들을 정리해 본다. 즉, 우선은 15장 부터 22장까지의 내용을 정리하고자 한다. 다른 장들은 전체적인 개념을 바탕으로 상세화 하여 설명한다고 볼 수 있어 여기서는 다루지 않겠다.
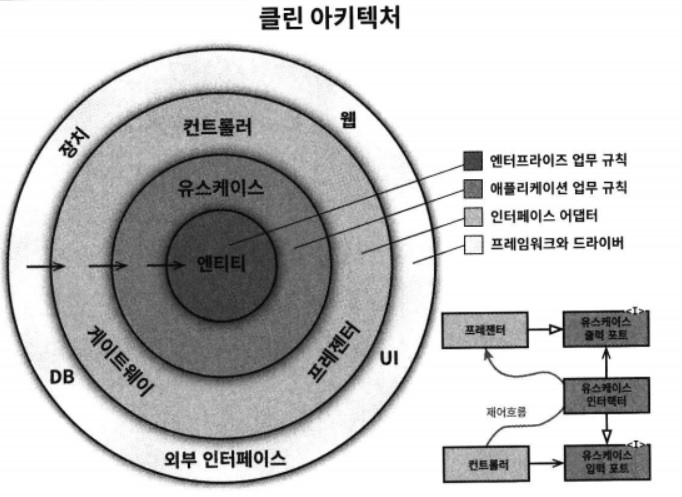
언급하는 주요 항목은 프로덕트 생명 주기 (개발, 배포 운영)를 고려하되, 소프트웨어 시스템을 지금까지 논의 한 컴포넌트로 분리하는 것인데, 이를 경계(Boundary)라고 하고 아키텍처 설계는 결국은 어떻게 경계를 나누는가에 대한 것이다. 소프트웨어를 시스템에서 정책(Policy)을 가장 핵심적인 요소로 식별하고 동시에 세부 사항(Detail)은 정책에 무관하게 만들어 이를 결정하는 일은 연기할 수 있게 한다. 더 구체적으로 보면, 정책, 레벨, 그리고 각각의 업무 원칙들을 어떻게 구획을 나누어 컴포넌트로 분리하는지에 대한 결합 분리(Decoupling, 디커플링)에대해 설명한다. 책에서 결국 주장하고자 하는 클린 아키텍처는 핵심 업무 규칙에 가장 엔터프라이즈 업무 규칙을 엔터티로 구분하고 이를 사용하여 구현하는 어플레케이션 업무 규칙을 유스 케이스 계층으로 본다. 이를 외부에서 사용하기 편하게 변환할 인터페이스 어댑터가 그 다음 계층이며 세부 사항인 외부 인터페이스를 프레임워크와 드라이버로 구분한다.
책에서는 좋은 아키텍처는 시스템이 모노리틱 구조(Monolithic Structure)로 태어나서 단일 파일로 배포되더라도, 이후에는 독립적으로 배포 가능한 단위들의 집합으로 성장하고 또 독립적인 서비스나 마이크로서비스 수준까지 성장할 수 있도록 만들어져야 한다고 이야기 한다. 각각의 상세 사항을 살펴 보자.
15장 아키텍처란
이책의 영어 원제는 Clean Architecture: a craftsman's guide to software structure and design 이다. 즉, 소프트웨어 크래트맨쉽을 강조하는 저자의 경험으로 소프트웨어 구조와 설계에 대한 가이드로서 아키텍처를 논하는 것이라 볼수 있다. 그래서, 저자는 아키텍트가 개발을 계속해야 한다고 한다. 이 부분에 대해서는 이견이 있을 수 있다.
저자는 소프트웨어 시스템의 아키텍처란 시스템을 구축했던 사람들이 만들어낸 시스템의 형태라고 한다. 이 형태는 개발, 배포, 운영, 유지보수되도록 만들어진다고 한다. 이러한 일을 용이하게 만들기 위해서는 가능한 한 많은 선택지를, 가능한 한 오래 남겨두는 전략을 따라야 한다고 이야기 한다.
개발: 팀 구조가 다르다면 아키텍처 관련 결정에서도 차이가 난다. 이를 콘웨이의 법칙으로 연결하여 설명하였다.
배포: 배포 비용이 높을수록 시스템의 유용성은 떨어진다. 따라서 소프트웨어 아키텍처는 시스템을 단 한 번에 쉽게 배포할 수 있도록 만드는 데 그 목표를 두어야 한다.
운영: 아키텍처가 시스템 운영에 미치는 영향은 개발, 배포, 유지보수에 미치는 영향보다는 덜 극적이다. 운영에서 겪는 대다수의 어려움은 단순히 하드웨어를 더 투입해서 해결할 수 있다. 이는 인터넷 서비스를 기준으로 하는 이야기로 보이며, 실재로 휴대폰과 같은 제품을 목표라면 제품의 비용이 적게 해야 할 수 있다. 하드웨어는 값싸고 인력은 비싸다는 말이 뜻하는 바는 운영을 방해하는 아키텍쳐가 개발, 배포, 유지보수를 방해하는 아키텍쳐보다는 비용이 덜 든다는 것이다. 즉, 인력/하드웨어 보다는 비용 측면에서 고려해야 하지 않을까? 상황에 따라 사람이 비쌀 때도 혹은 프러덕트의 다른 요소의 비용이 높을 수도 있다고 생각한다.
유지보수: 유지보수는 모든 측면에서 봤을 때 소프트웨어 시스템에서 비용이 가장 많이 든다. 새로운 기능은 끝도 없이 행진하듯 발생하고 뒤따라서 발생하는 결함은 피할 수 없으며, 결함을 수정하는 데도 엄청난 인적 자원이 소모된다.
모든 소프트웨어 시스템은 주요한 두 가지 구성요소로 분해할 수 있다. 바로 정책(Polciy)과 세부사항(Detail)이다. 정책 요소는 모든 업무 규칙(Business Rules)과 업무 절차(Procuedures)를 구체화 한다. 정책이란 시스템의 진정한 가치가 살아 있는 곳이다. 세부사항은 사람, 외부 시스템, 플그래머가 정책과 소통할 대 필요한 요소지만, 정책이 가진 행위에는 조금도 영향을 미치지 않는다. 이러한 세부 사항에는 입출력 장치, 데이터 베이스, 웹 시스템, 서버, 프레임워크, 통신 프로토콜 등이 있다.
아키텍트의 목표는 시스템에서 정책을 가장 핵심적인 요소로 식별하고 동시에 세부사항은 정책에 무관하게 만들 수 있는 형태의 시스템을 구축하는 데 있다. 세부사항을 결정하는 일은 미루거나 연기할 수 있게 된다. 요점을 파악했을 것이다. 세부사항에 몰두하지 않은 채 고수준의 정책을 만들 수 있다면, 이러한 세부사항에 대한 결정을 오랫동안 미루거나 연기할 수 있다. 이러한 결정을 더 오래 참을 수 있다면, 더 많은 정보를 얻을 수 있고, 이를 기초로 제대로 된 결정을 내릴 수 있다. 선택 사항을 더 오랫동안 열어 둘 수 있다면 더 많은 실험을 해볼 수 있고 더 많은 것을 시도할 수 있다. 그리고 결정을 더 이상 연기할 수 없는 순간이 닥쳤을 대 이러한 실험과 시도 덕분에 더 많은 정보를 획득한 상태일 것이다. 좋은 아키텍트는 결정되지 않은 사항의 수를 최대화 한다.
16장 독립성.
좋은 아키텍처는 결국은 요구 사항을 지원해야 한다. 클린 아키텍처에서도 이 요구 사항을 시스템의 유스케이스를 지원해야 한다고 이야기 한다. 여기에 추가로 아키텍처는 이전에 이야기 한 프러덕트의 라이프 싸이클 중에서 유지 보수를 제외한 운영, 개발, 배포 관점에서도 지원해야 한다고 이야기 한다.
어쩌 보면, 아키텍처는 시스템의 행위에 그다지 큰 영향을 주지 않는다. 다른 말로 행위와 관련하여 아키텍처가 열어 둘 수 있는 선택사항은 거의 없다. 좋은 아키텍처가 행위를 지원하기 위해 할 수 있는 일 중 에서 가장 중요한 사항은 행위를 명확히 하고 외부로 드러내며, 이를 통해 시스템이 지닌 의도를 아키텍처 수준에서 알아 볼 수 있게 만드는 것이다. 이 부분은 뒤에도 나오지만, "소리치는 아키텍처"로 다르게 표현하기도 한다.
아키텍처를 구조적인 분리로 보면, 계층(Layer)와 유스 케이스(Use Case) 차원에서 분리로 볼 수 있다. 계층 디커플링/결합 분리 (Decoupling Layers) 측면에서 보면, 사용자 인터페이스(User Interface, UI)가 변경되는 이유는 업무 규칙(Business Rule)과는 아무런 관련이 없다. 만약 유스케이스가 두 가지 요소를 모두 포함한다면, 뛰어난 아키텍트는 유스케이스에서 UI부분과 업무 규칙 부분을 서로 분리하고자 할 것이다.
업무 규칙은 그 자체가 애플리케이션과 밀접한 관련이 있거나, 혹은 더 범용적일 수도 있다. 예를 들어 입력 필드 유효성 검사는 애플리케이션 자체와 밀접하게 관련된 업무 규칙이다. 계좌의 이자 계산이나 재고품 집계는 업무 도메인에 더 밀접하게 연관된 업무 규칙이다. 이들 서로 다른 두 유형의 규칙은 각자 다른 속도로 그리고 다른 이유로 변경될 것이다. 이들 규칙은 서로 분리하고, 독립적으로 변경할 수 있도록 만들어야 한다. 즉, 분리/디커플링 해야 한다.
서로 다른 이유로 변경되는 것에 유스케이스 그 자체가 포함된다. 이를 유스 케이스 디커플링 (Decoupling Use Cases)이라고 한다. 주문 입력 시스템에서 주문을 추가하는 유스케이스는 주문을 삭제하는 유스케이스와는 틀림없이 다른 속도로 그리고 다른 이유로 변경된다. 유스케이스는 시스템을 분할하는 매우 자연스러운 방법이라고 설명한다.
결합 분리/디커플링(Decoupling)[1]
이렇게 분리된 컴포넌트를 서로 다른 서버에서 실행해야 하는 상황이라면, 이들 컴포넌트가 단일 프로세서의 동일한 주소 공간에 함께 상주하는 형태로 만들어져서는 안 된다. 분리된 컴포넌트는 반드시 독립된 서비스가 되어야 하고 일종의 네트워크를 통해 서로 통신해야 한다. 많은 아키텍트가 이러한 컴포넌트를 '서비스(Service)' 또는 '마이크로서비스(Microservice)라고 하는데, 그 구분 기준은 모호한 면이 있다. 실제로 서비스에 기반한 아키텍처를 흔히들 서비스 지향 아키텍처(Service-oriented architecture SOA)라고 부른다.
17장 경계: 선 긋기
소프트웨어 아키텍처는 선을 긋는 기술이며, 저자는 이 선을 경계(boundary)라고 부른다. 경계는 소프트웨어 요소를 서로 분리하고, 경계 한편에 있는 요소가 반대편에 있는 요소를 알지 못하도록 막는다. 아키텍트가 내리는 경계의 결정이 핵심적인 업무 로직을 오염시키지 못하게 만들려는 목적으로 쓰인다. 그러면서, 이케텍트의 목표는 필요한 시스템을 만들고 유지하는 데 드는 인적 자원을 최소화하는 것이라는 사실을 상기하자. 로버트 마틴은 인적 자원이 가장 비싼 자원으로 보고 있다.
어떤 종류의 결정이 이른 결정일까? 바로 시스템의 업무 요구사항, 즉 유스케이스와 아무런 관련이 없는 결정이다. 프레임워크, 데이터베이스, 웹 서버, 유틸리티 라이브러리, 의존성 주입에 대한 결정 등이 여기 포함된다.
어떤게 선을 그을까? 그리고 언제 그을까? 이와 관련된 답으로는 관련이 있는 것과 없는 것 사이에 선을 긋는 것이 기본 규칙이라 할 수 있다. GUI는 업무 규칙과는 관련 없기 때문에, 이 둘 사이에는 반드시 선이 있어야 한다. 데이터베이스는 GUI와는 관련이 없으므로, 이 둘 사이에도 반드시 선이 있어야 한다. 데이터베이스는 업무 규칙과 관련이 없으므로, 이 둘 사이에도 선이 있어야 한다.
업무 규칙(Business Rules)에 플러그인으로 연결하기[1]
두 컴포넌트 사이에 이러한 경계선을 그리고 화살표의 방향이 Business Rules를 향하도록 만들었으므로, Busines Reules에서는 어떤 종류의 데이터 베이스도 사용할 수 있음을 알 수 있다. Database 컴포넌트는 다양한 구현체로 교체될 수 있으며, Business Rules는 조금도 개의치 않는다. GUI는 다른 종류의 인터페이스로 얼마든지 교체할 수 있으며 BusinessRules는 전혀 개의치 않는다는 사실을 알 수 있다. 데이터베이스와 GUI에 대해 내린 두 가지 결정을 하나로 합쳐서 보면 컴포넌트 추가와 관련한 일종의 패턴, 즉, 플러그인 아키텍처가 만들어진다.
18장 경계 해부학(Boundary Anatomy)
위와 같이 분리된 일련의 소프트웨어 컴포넌트와 그 컴포넌트들을 분리하는 경계를 통해서 시스템 아키텍처가 정의 된다. 런타임에 경계를 횡단한다함은 그저 경계 한쪽에 있는 기능에서 반대편 기능을 호출하여 데이터를 전달하는 일에 불과하다. 적절한 위치에서 경계를 횡단하게 하는 비결은 소스 코드 의존성 관리에 있다.
단일체로 변역하는 모노리틱(Monolithic) 구조는 쉽게 이야기 하면, 단일 실행 파일에 지나지 않는다. 이 파일은 정적으로 링크된 C/C++ 프로젝트이거나, 실행 가능한 jar 파일로 묶인 일련의 자바 클래스 파일이거나, 단일 .EXE파일로 묶인 일련의 .NET 바이너리등일 것이다.
배포형 컴포넌트(library, jar, DLL), 스레드, 로컬 프로세스(OS상의 Process), 서비스(물리적으로도 분리된 컴퓨팅 리소스에서 동작) 등으로 컴포넌트들을 분리하는 방법들이 있을 수 있다.
19장 정책과 수준
소프트웨어 시스템이란 정책(Policy)을 기술한 것이다. 실제로 컴퓨터 프로그램의 핵심부는 이게 전부다. 컴포터 프로그램은 각 입력을 출력으로 변환하는 정책을 상세하게 기술한 설명서다. 대다수의 주요 시스템에서 하나의 정책은 이 정책을 서술하는 여러 개의 조그만 정책들로 쪼갤 수 있다. 예를 들어 집계와 관련된 업무 규칙을 처리하는 방식을 서술하는 조그만 정책이 있을 수 있다. 그리고 특정 보고서를 어떤 포맷으로 만들지 서술하는 또 다른 정책이 있을 수 있다. 또한 입력 데이터를 어떻게 검증할지를 서술하는 정책이 있을 수 있다.
수준(Level)을 엄밀하게 정의하자면 '입력과 출력까지의 거리'다. 시스템의 입력과 출력 모두로 부터 멀리 위치할 수록 정책의 수준은 높아진다. 입력과 출력을 다르는 정책이라면 시스템에서 최하위 수준에 위치한다.
정책을 컴포넌트로 묶는 기준은 정책이 변경되는 방식에 달려 있다는 사실을 상기하자. 단일 책임 원칙(SRP)와 공통 폐쇄 원칙(CCP)에 따르면 동일한 이유로 동일한 시점에 변경되는 정책은 함께 묶인다. 고수준 정책, 즉 입력과 출력에 서부터 멀리 떨어진 정책은 저수준 정책에 비해 덜 빈번하게 변경되고, 보다 중요한 이유러 변경되는 경향이 있다.저수준 정책, 즉 입력과 출력에 가까이 위치한 정책은 더 빈번하게 변경되며, 보다 긴급성을 요하며, 덜 중요한 이유로 변경되는 경향이 있다.
이처럼 모든 소스 코드 의존성의 방향이 고수준 정책을 향할 수 있도록 정책을 분리했다면 변경의 영향도를 줄일 수 있다. 시스템의 최저 수준에서 중요하지 않지만 긴급한 변경이 발생하더라도, 보다 높은 위치의중요한 수준에 미치는영향은 거의 없게 된다.
20장 업무 규칙
업무 규칙(Business Rules)은 사업적으로 수익을 얻거나 비용을 줄일 수 있는 규칙 또는 절차다. 더 엄밀하게 말하면 컴퓨터 상으로 구현했는지와 상관없이, 업무 규칙은 사업적으로 수익을 얻거나 비용을 줄일 수 있어야 한다. 심지어 사람이 수동으로 직접 수행하더라도 마찬가지다. 이러한 규칙을 핵심 업무 규칙(Criticial Business Rule)이라고 부를 것이다. 왜나하면 이들 규칙은 사업 자체에 핵심적이며, 규칙을 자동화하는 시스템이 업서라도 업무 규칙은 그대로 존재하기 때문이다. 핵심 업무 규칙은 데이터를 요구하는데, 책에서는 이를 핵심 업무 데이터(Critical Business Data)라고 부르고 있다.
핵심 규칙과 핵심 데이터는 본질적으로 결합되어 있기 때문에 객체로 만들 좋은 후보가 된다. 우리는 이러한 유형의 객체를 엔티티(Entity)라고 부른다.
유스케이스 자동화된 시스템이 동작하는 방법을 정의하고 제약함으로써수익을 더거나 비용을 줄이는 업무 규칙도 존재한다. 바로 이것이 유스케이스(Use case)다. 유스케이스는 애플리케이션에 특화된 업무 규칙(Application-specific Business Rules)을 설명한다.
21장: 소리치는 아키텍처
여러분의 애플리케이션 아키텍처는 뭐라고 소리치는가? 상위 수준의 디렉터리 구조, 최상위 패키지에 담긴 소스 파일을 볼 때, 시스템의 본질을 이야기 하는가? 즉, "핼스 케어 시스템이야" 또는 "재고 관리 스스템이야"라고 소리치는가? 아니면 사용하고 있는 디테일인 프레임워크에 대해서 이야기 하고 있는가? 예를 들자면, "레일스(Rails)야", "스프링(Spring)/하이버네이트(Hibernate)야", 아니면 "ASP야"라고 소리치는가?
책에서는 좋은 아키텍처는 유스케이스를 그 중심에 두기 때문에, 프레임워크나 도구 환경에 전혀 구애받지 않고 유스케이스를 지원하는 구조를 아무런 문제 없이 기술 할 수 있다고 이야기 한다. 좋은 소프트웨어 아키텍처는 프레임워크, 데이터베이스, 웹 서버, 그리고 여타 개발 환경 문제나 도구에 대해서는 결정을 미룰 수 있도록 만든다.
프레임워크는 열어 둬야 할 선택사항이다. 좋은 아키텍처는 프로젝트의 훨씬 후반까지 레일스, 스프링, 하이버네이트, 톰갯(Tomcat), MySQL에 대한 결정을 하지 않아도 되도록 해준다. 프레임워크, 데이터베이스, 웹 서버, 여타 개발환경 문제나 도구에 대한 결정을 미룰 수 있어야 한다. 프레임워크는 매우 강력하고 상당히 유용할 수 있다. 하지만, 프레임워크는 도구일 뿐, 삶의 방식은 아니다.
22장: 클린 아키텍처
책에서는 다른 아키텍처 접근 방법에 대해서 설명한다. 이 접근 법들도 목표가 같은데, 바로 관심사의 분리(Seperation of concerns)다. 모두 소프트웨어를 계층으로 분리함으로써 이 관심사의 분리라는 목표를 달성한다고 한다.
이들 아키텍처는 모두 시스템이 다음과 같은 특징을 지니도록 만든다. . 프레임워크 독립성 . 테스트 용이성 . UI 독립성 . 데이터베이스 독립성 . 모든 외부 에이전시에 대한 독립성
아래 다이어그램은 이들 아키텍처 전부를 실행 가능한 하나의 아이디어로 통합하려는 시도라고 이야기 한다. 즉, 핵심 개념도로 볼 수 있으며 지금까지 이야기 한 부분에 대한 큰 그림으로 이해할 수 있다.
클린 아키텍처[1]
의존성 규칙
클린 아키텍어 다이어 그램에서 안으로 들어갈 수록 고수준의 소프트웨어가 된다. 바깥쪽 원은 메커니즘이고 안쪽 원은 정책이다. 여기서 가장 중요한 규칙은 의존성 규칙(Dependency Rule)이다. 즉, 소스코드 의존성은 반드시 안쪽으로, 고수준의 정책을 향해야 한다. 내부의 원에 속한 요소는 외부의 원에 속한 어떤 것도 알지 못한다. 함수, 클래스, 변수, 그리고 소프트웨어 엔티티로 명명되는 모든 것이 포함된다. 같은 이유로, 외부의 원에서 선언된 데이터 형식도 (Data Type)도 내부의 원에서 절대로 사용해서는 안 된다.
엔티티
엔티티는 전사적인 핵심 업무 규칙을 캡슐화한다. 엔티티는 메서드를 가지는 객체이거나 일련의 데이터 구조와 함수의 집합이다. 운영 관점에서 특정 애플리케이션에 무언가 변경이 필요하더라도 엔티티 계층에는 절대로 영향을 주어서는 안 된다.
인터페이스 어댑터
인터페이스 어댑터(Interface Adapter) 계층은 일련의 어댑터들로 구성된다. 어댑터는 데이터를 유스케이스와 인터티에게 가장 편리한 형식에서 데이터베이스나 웹 같은 외부 에이전시에게 가장 편리한 형식으로 변환한다. GUI의 MVC 아키텍처를 모두 포괄한다. 프레젠터(Presenter), 뷰(View), 컨트롤러(Controller)는 이 계층에 속한다. 모델은 그저 이 계층에서 사용되는 데이터 구조로 보면 된다.
프레임워크와 드라이버
클린 아키텍처 그림에서 가장 바깥쪽 계층은 일반적으로 데이터베이스나 웹 프레임워크 같은 프레임워크나 도구들로 구성 된다. 이는 안쪽 원과 통신하기 위한 접합 코드로 볼 수 있다.
원은 네 개여야만 하나?
이 다이어 그램은 개념을 설명하기 위한 하나의 예시로, 실재 시스템에서는 더 많은 원이 필요할 수도 있다. 하지만, 어떤 경우에도 의존성 규칙은 적용된다. 소스 코드 의존성은 항상 안쪽으로 향한다. 안쪽으로 이동할 수록 추상화와 정책의 수준은 높아진다. 가장 바깥쪽 원은 저수준의 구체적인 세부사항으로 구성된다.
경계 횡단하기
그림의 우측 하단 다이어그램에 원의 경계를 횡단하는 방법을 보여 주는 예시가 있다. 컨트롤러와 프레젠터가 다음 계층에 속한 유스케이스와 통신하는 모습을 확인할 수 있다. 우선 제어흐름에 주목해 보자. 제어흐름은 컨트롤러에서 시작해서, 유스케이스를 지난후, 프레젠터에서 실행되면서 마무리 된다. 이와 상반되게 의존성은 반대이다.이와 같은 경우, 대체로 의존성 역전 원칙을 사용하여 해결한다.
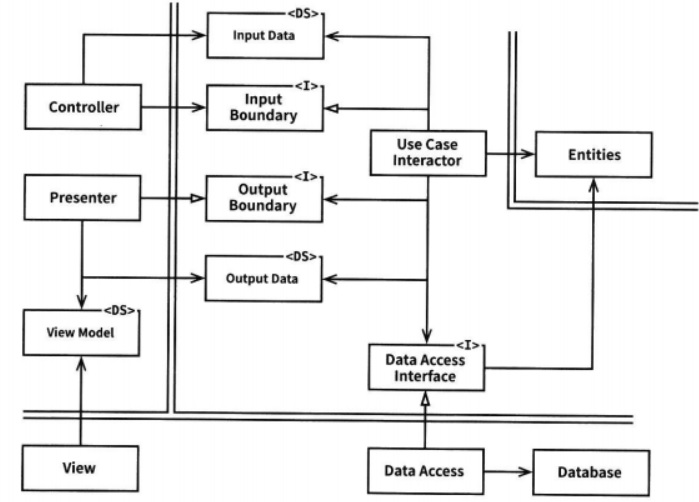
경계를 가로지르는 데이터는 흔히 간단한 데이터 구조로 이루어져 있다. 기본적인 구조체나 간단한 데이터 전송 객체(Data Transfer Object)등 원하는 대로 고를 수 있다. 또는 함수를 호출할 때 간단한 인자를 사용해서 데이터로 전달할 수도 있다. 그게 아니라면 데이터를 해시맵으로 묶거나 객체로 구성할 수도 있다.
전형적인 시나리오
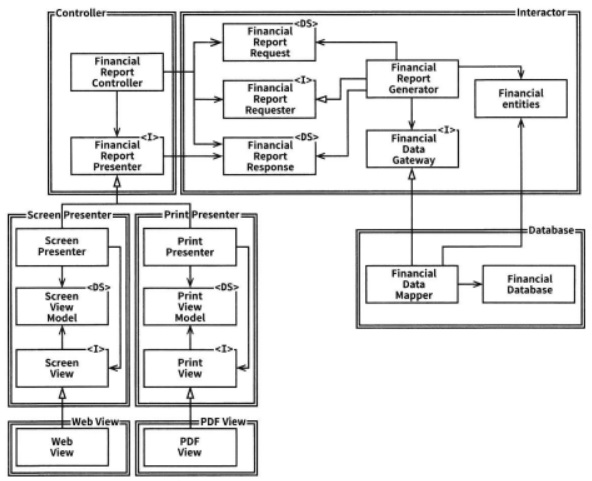
이 클린 아키텍처의 예로서 전형 적인 웹 서비스 아키텍처를 아래 그림에서 살펴 볼 수 있다. 웹 서버는 사용자로 부터 입력 데이터를 모아서 좌측 상단의 Controller로 전달한다. Controller는 데이터를 평범한 자바객체(POJO)로 묶은 후, InputBoundary 이터페이스를 통해 UseCaseInsteractor로 전달한다. UseCaseInteractor는 이 데이터를 해석해서 Entities가 어떻게 춤출지를 제어하는데 사용한다.
전형적 웹 서비스 구조[1]
결론
클린 아키텍처에서 주장하는 가장 핵심 적인 것을 보통 클린 아키텍처 다이어 그램에서 이야기 하는 4가지 영역의 분리라고 볼 수 있다. 서론에서도 이야기 했듯이 아키텍처의 구조적인 측면에서 경계(Boundary)를 만드는 것이 가장 중요한 일일 수 있다. 다른 말로 관심사의 분리(Separation of Concern)이라고도 했다.
이 분리의 주된 목적은 변경이 필요할 때, 영향을 받지 않는 부분을 분리하자는 것이다. 이렇게 하기 위해 가장 먼저 분리 한 것은 정책(Policy)와 세부 사항(Detail)이다. 그림에서는 프레임워크/드라이버와 나머지가 분리되었다고 볼 수 있다. 정책에서는 업무 규칙 중에서도 유스 케이스에서 더 핵심적인 것을 분리해서 엔터프라이즈 업무 규칙과 유스 케이스 업무 규칙이 분리되고 이 것들이 외부의 세부 사항과 연결하기 위한 영역으로 인터페이스 어댑터를 둔 것으로 볼 수 있다.
이 구조에서 가장 중요한 원칙이 의존성 규칙이라고 했다. 즉, 내부 영역이 외부 영역에 의존하면 안되고 몰라야 한다는 것이다. 혹시 제어 흐름이 반대인 것은 의존성 역전 원칙(DIP)를 적용하는 것도 언급하였다. 이렇게 하면서, 세부 사항들은 늦게 결정하도록 하면서 여러 시험을 통해 더 좋은 선택을 할 수 있게 한다고 이야기 하고 이 것이 좋은 아키텍처, 클린 아키테처라고 주장한다.
애자일과 소프트웨어 크래프트맵쉽을 중시하는 저자의 철학과 연결되는 것이 제품/프러덕트가 모노리틱 구조(Monolithic Structure)로 태어나고, 성장하고, 분화 한다고 이야기로 보인다. 이렇게 분화한 것이 독립적인 서비스(Service Oriented Architecture, SOA)나 마이크로서비스(Microservice Architecture)가 된다고 한다.
참고 문헌
[1] 로버트 C. 마틴 저, "클린 아키텍처 소프트웨어 구조와 설계의 원칙" 인사이트(insight) 2019년 08월 20일, 송준이 역
이 글은 재미있고, 꽤 알려진 애자일의 법칙들을 모아 놓은 글이다. 사실 이야기를 기존에 알고 있던 것은 콘웨이 법칙 뿐이었고 내용을 들은 것은 "프로젝트가 지연될 때 인력을 추가하면 더 늦어 진다"라는 것인데, 이 것이 맨먼스 미신의 저자인 브룩의 법칙이라고 불리는지 몰랐다. 또한, 다른 법칙들도 통찰이 있는 말들이다. 그래서, 곱씹어 보고 생각도 해볼 만한 내용들이다.
글은 [1]에서 가져온 것이다.
애자일 법칙: 콘웨이, 브룩, 해크먼, 굿하트, 라만 그리고 파킨슨 법칙
심리학, 조직 설계 또는 소프트웨어 공학의 관찰, 휴리스틱 및 멘탈 모델의 긴 리스트의 분야에서 분산 애자일 팀과 특히 관련이있는 6 가지 "애자일 법칙"을 선정한다.
콘웨이의 법칙
멜 콘웨이(Mel Conway)는 1968년 그의 논문에서 처음으로 다음과 같이 주장했다.
"(광범위하게 정의된) 시스템을 설계하는 조직은 조직의 커뮤니케이션 구조의 동일한 구조를 가지는 시스템 디자인을 만든다." (출처.)
다시 말해, 두 팀이 응용 프로그램의 일부를 별도로 구축하는 경우 해당 시스템에는 두 가지 구성 요소가 있을 수 있으며 이로 인해 종속성과 추가 통신 오버 헤드가 발생한다.
그것은 항상 도전이었다. 팀이 함께 있으면 커피 또는 워터 쿨러를 통해 비공식적으로 문제를 협상할 수 있다. 분산 된 팀의 경우 기회가 줄어 들고, 추가적인 커뮤니케이션 오버 헤드가 발생하며, 또한 추가적인 원격 회의를 공식적으로 진행해야 한다.
이를 분산된 애자일 팀에 적용하려면 중간 관리자와 조직이 맏닥뜨린 실제 또는 인지된 위기로 돌아가야 한다. 원격 및 종종 비동기식 통신으로 인해 감지된 통제력 상실과 통신 문제에 대해서 가시성을 확보하려는 충동은 더 많은 보고서, 더 많은 지표 및 더 많은 회의와 같이 더 타이트하게 조직을 운영하려는 경향이 있다.
이제 조직이 유연하면서도 탄력적인 조직 구조를 만드는 데 실패하는 이유가 무엇인지 물어볼 수 있다. 크레이그 라만(Craig Larman)은 그 이유를 다음과 같이 공식화하여 만들었다.
"조직은 중간 및 1차 관리자 와"전문가"직위 및 권력 구조를 현 상태에서변경하지 않도록 암묵적으로 최적화되어 있다." (출처.)
이 관찰은 변화에 대한 시스템 사고 방식을 반영한다. 사람들의 행동을 바꾸려면 먼저 시스템을 변경해야 한다. 기본 시스템을 변경하지 않고 조직의 문화를 변경하려는 시도는 실패한다. 따라서 위기에 대응하기 위해 현재 부과된 변화의 필요성은 단순히 운영 또는 전술적 절차가 아닌 시스템 자체를 목표로 해야한다.
파킨슨의 법칙
애자일 팀에서 시간 제한이 그토록 가치있는 관행 인 이유는 간단하다. "작업은 완료 할 수있는 시간을 채우기 위해 확장된다.(Work expands so as to fill the time available for its completion)" (Parkinson의 법칙.)
복잡한 환경에서 가치 있고 지속 가능하며 수익성이있는 제품을 만들려고 할 때 빠른 피드백 루프가 필수적이다. 구축, 측정, 학습. 출시 전에 너무 오래 기다리거나 완벽을 추구하는 것은 선택 사항이 아니다. 대신 스프린트, 사이클, 반복, 검사 및 적응이 사용되는 실천 사항들의 이름이다. 우리는 시장과 동기화 할 수있을 만큼 빠르게 반복하는 것을 목표로하지만 너무 짧은 스프린트로 너무 많은 오버 헤드를 피하는 것을 목표로 한다.
분산된 애자일 팀의 문제는 출시 루틴이 때로 학습 부분보다 더 가치가 높은 경향이 있다는 것이다. 물론 "학습"은 원격 환경에서 더 어렵지만 불가능하지는 않다. 그러나 불확실성을 해결하기 위한 행동에 대한 편견을 완화하기 위해 출시 부분에 초점을 맞추면서, 우리는 고객을 대신하여 문제를 해결하는 자율팀 팀을 구성하는 것과 반대되는 기능 공장이되는 데 더 가까워지고 있다.
애자일 법칙-결론
분산된 애자일 팀으로 일하는 것은 많은 조직에서 기존의 조직, 기술 및 문화적 문제를 증폭한다. 그런 점에서 '애자일 법칙'을 재검토하는 것은 이러한 장애를 해결하는 데 도움이되는 것으로 입증되었다. 아마도 이러한 문제를 유리하게 사용할 수도 있다. 사람들이 말하듯이, "모든 문제는 기회이다.(Every problem is an opportunity.)"
최근에 이러한 애자일 법칙을 경험 한 적이 있는가? 그렇다면 우리와 당신의 의견을 공유부탁한다.
번역을 마치고...
서두에도 적었지만, 알고 있었지만 출처가 불명확했던 것들도 많이 있다. 이러한 원칙들을 살펴 보는 것은 실재로 조직을 애자일하게 운영하는데 도움이 되는 기본 원리를 이해하는데도 도움이 된다고 볼 수 있다.
나는 사람들이 시도하고 종종 실패함에 따라 OKR을 구현하는 핵심에 대해 최근에 많은 좋은 대화를 나누었다. OKR 사용시 문제로 이어지는 패턴이 있다.
분기당 OKR을 너무 많이 설정했다.
하나만 설정하자. 구글은 검색 엔진과 브라우저를 개발하고 소셜 네트워크 서비스를 하며 자율 주행 차를 만들려고하기 때문에 회사에 여러 OKR이 필요하다. 그들이 "모든 제품을 최고로 사회적이 되도록 만들기(Make all products supremely social)"라는 단일 목표를 설정했다고 상상해보자. 자율 주행 자동차 개발 하는 사람들은 키트(나이트 라이더 드라마 참조)를 만는 것일 수 있다. 그러나 대부분의 회사 (그리고 다른 모든 스타트업)은 하나의 대담한 OKR을 통해 조직을 통합하고 노력이 투여 되도록 한다.
일주일 또는 한 달 동안의 OKR을 설정한다.
나는 스타트 업의 목표(Objective)가 “제품/시장 적합성 찾기(find product/market fit)”가 아니라면, 제품/시장 적합성(product/market fit)을 달성하기 전에 OKR을 사용해야한다고 완전히 확신하지는 못한다. 일주일 이상 추적 할 수 없다면 아마도 OKR을 할 준비가되지 않은 것이다. 제품/시장에 적합을 찾고 있다면, 3개월 전체에 걸쳐 진행하라. 결국, 그보다 짧은 시간 내에 할 수있는 진정 대담한 일은 무엇인가? 1 주일 안에 할 수 있다면 그 것은 그저 작업 일 것이다.
메트릭 기반 목표를 설정한다.
이것은 많은 경우 MBA로의 몰락이다. 당신은 숫자를 좋아한다. 당신은 돈을 사랑한다. 모두가 아닌가? OKR은 다분야 팀(multidisciplinary teams)을 통합하며 이는 꿈꾸는 디자이너, 이상주의 엔지니어 및 배려하는 고객 서비스를 의미한다. 목표는 영감을주는 것이어야하며, 사람들이 침대에서 뛰어 내려 새로운 하루와 새로운 도전에 대비할 수 있도록하는 콜 투 액션(call-to-action)하는 문장이어야 한다.
주요 결과가 결과(Results)가 아니라 작업(Task)이다.
OKR에 대한 이 글을 작성하고 처음 다시 읽었을 때 나는 약간의 불안감을 느꼈다. 주요 결과의 예제가 여기 저기에 있었기 때문이다. "온라인 코칭 리소스에서 교육 자료를 검토한다." 이 핵심 결과는작업이며 완료하는 데 한 분기가 소요되지 않는다. "주간 소통 회의 평가를 X %에서 Y %로 높인다."라는 KR은 적절하다. 핵심 결과(Key Result)는 당신이하는 일이 아니라 당신이 한 일 때문에 일어난 일이다. 작업(Task)는 주간 우선 순위 목록에 저장해 두자.
확신 수준(confidence level)을 설정하지 않는다.
핵심 결과(Key Results)의 70 %를 달성 할 것으로 예상한다는 이야기를 많이 듣는다. 그래서, 사람들이 목표 두 개를 쉽게 설정하고 하나를 엄청나게 어렵게 만드는 회사의 사례를 많이 들었다. 요점은 이것이 아니다. OKR은 문 샷(Moon shot)를 하도록 격려하기 위해 있다. 당신이 진정 무엇을 할 수 있는지 보여주기 위한 것이다.
확신 수준을 10 점 만점에 5 점으로 설정하면 목표를 달성 할 확률이 50 %입니다. 그것은 자신의 목표를 스트레칭하는 것이다.
변화하는 확신 수준(confidence level)을 추적하지 않는다.
분기의 마지막 달에 와서 갑자기 OKR에 주의를 기울이는 것을 잊었다는 것을 깨닫는 것보다 더 짜증나는 것은 없다. 새로운 정보를 얻으면 변경 사항을 표시하자. 팀원에게 오랫동안 확신 수준이 5이었음을 상기시자. 도움을 제공하라.
논의가 필요한 것에 대해 토론하라. 우선 순위가 정말로 핵심 결과를 움직일까? 다가오는 프로젝트의 로드맵에 조정이 필요한가? 팀의 건강 상태는 어떻고 그 이유는 무엇인가?
당신은 금요일에 강하게 이야기한다.
우리는 일주일 내내 자신과 서로에게 강인하다. 우리가 한 일에 대해 맥주를 마시고 건배하자. 특히 주요 결과를 모두 달성하지 못할 경우, 큰 목표를 설정하여 달성 할 수 있었던 것이 무엇인지에 대해 자랑스럽게 생각하자.
OKR을 성과 검토(performance review)의 일부로 만든다.
Google에서 Zynga, Swipely에 이르기까지 모든 사람들이 이에 대해 경고한다. 사람들이 높은 목표를 달성하기를 원한다면 터무니없는 목표를 달성하지 못했다고 처벌 할 수 없다. 대신 직원은 주간 상태 메일과 OKR을 사용하여 자신이 수행 한 작업에 대한 자체 검토를 작성할 수 있다. 별을 노릴 때, 문 샷 프로젝트를 달성할 수 있다.
퀵 팁
여러 비즈니스 라인이없는 경우 회사에 대해 하나의 OKR 만 설정하라. 집중에 관한 것이다.
하나의 OKR에 한 분기(3 개월)을 할당하라. 일주일 안에 할 수 있다면 얼마나 대담할까?
목표(Objective)에서 지표가 멀어지게 하자. 목표(Objective)는 영감을주는 것이다.
주간 체크인에서 회사 OKR로 시작하고 그룹의 것을 만들자. 개인 별로 하나 하나 모든 처리하지 말자. 그것은 개인 1:1 미팅에서 하는 것이 더 좋다. 예를 들면, 당신은 매주 어떤 OKR을 가지는가가 1:1 미팅에서의 질문이 될 것이다.
OKR 캐스케이드디도록 하자. 회사 OKR, 그룹/역할, 개인 순으로 설정한다.
OKR은 당신이하는 유일한 일이 아니라 당신이해야하는 한가지 일이다. 사람들이 배를 계속 움직이기를 기대하자.
월요일 OKR 체크인은 대화이다. 확신 레벨, 건강 지표 및 우선 순위의 변화에 대해 논의하자.
직원이 회사 OKR을 제안하도록 장려하자. OKR은 단지 하향식으로 동작만하는 것이 아니라 상향식으로 동작하는 것도 훌륭하다.
이 글은 퍼스널 OKR 보다는 회사 OKR에 대한 것이라는 생각이 된다. 하지만, Key Results와 주간 타스크, 일일 타스크를 구분하는 것은 필요할 수 있겠다.
참고 문헌
[1] 크리스티나 워드케 (지은이),박수성 (옮긴이), "구글이 목표를 달성하는 방식 OKR", 한국경제신문 2018-11-23 원제 : Radical Focus: Achieving Your Most Important Goals with Objectives and Key Results (2016년)
이글[1]은 [2]의 저자인 크리스티나 워드케가 블로그에 작성한 글이다. Personal OKR에 대해서 자신의 생각과 팁들을 정리한 글이다. 이 글 이후에 작성한 것도 있으니 참고하면 좋겠다.
Personal OKRs
나는 OKRS (Objectives and Key Results)에 열광한다. 나는 내가 함께 일하는 모든 스타트업에게 회사의 목표를 향해 나아가는 이 시스템을 전파해 왔으며 그 결과는 항상 인상적이다. 불완전하게 구현된 경우에도 회사가 필요로하는 소통와 생각을 만들어 낸다. 그래서 내 자신이 정체되고 개인적인 삶을 발전시킬 수 없다는 것을 알았을 때 즉시 제대로 돌려 놓지 못하는 것이 충격적입니다. 다행히도 저는 제 문제를 해결하기 위해 제 자신의 도구에 대해서 살펴 보도록 상기시켜 준 훌륭한 코치와 함께 하고 있었다.
그래서 먼저 1분기의 목표를 설정했다. 목표는 시간이 제한 될 때 항상 가장 잘 작동한다. 저는 3 개월이라는 시간 간격을 매우 좋아 한다. 중요한 일을 수행하기에 충분히 길고 긴박감을 느낄 수있을 만큼 짧다. 물론 회사는 분기에 매핑되기 때문에 좋아한다.
목표는 질적으로 높고 구체적이며 대담해야한다
나의 목표는 지속 가능한 행복한 삶을 구축하는 것이었다. 미안하지만, 너무 크고 모호하다! 그것은 인생의 사명에 가깝습니다. 그렇다면 3 개월 동안의 목표는 무엇일까?
목표(Objective) : 건강을 지키고 내가 좋아하는 일을하면서 재정적으로 안정되어야한다. 재정적 안정 : 최저 지출 수준 일 때 지출하는만큼 벌어들인다. 건강 유지 : 나는 끔찍한 위장과 허리 문제를 겪었다. 너무 많은 책상 시간. 스트레스로 인해 위통. 내가 좋아하는 일 : 돌아 보면, 이것은 나를 곤란하게 만들었다. 너무나 쿨하고 멋지다고 생각하는 일이 너무 많다. 지루하지 않기 위해서 내 건강을 해치는 일을 했다.
그래서 지금은 주요 결과(Key Results, KR)이 필요했다. 이 세 가지가 있으면 내 목표에 도달했음을 알수 있다.
KR : 월급을받지 않아도 다른 일을하면서 3 개월 동안 X를 벌기 KR : 확장을 예측하기 위한 관리 가능한 예산 보유 하기 KR : 위산 역류 없음, 요통 없음
X는 친절한 재정 어드바이져와 함께 내 인생을 평가했을 때 나온 결과가 적혀있는 봉투의 뒷면에 적혀있던 수치였다. 그러나 나는 재정 상태를 더 잘 측정하고 이를 Anthropologie(어떤 SNS 서비스 같은데 현재는 검색해도 옷 매장만 나옴)에서 언제 자랑 할 수 있는지 알기 위해 더 정확한 정보를 얻고 싶었다. 나는 내 예산을 한 번도 소진 한 적이 없지만 그것이 제 삶이 지속 가능한지 알 수있는 유일한 방법이라고 생각했습니다.
다음으로 계획이 필요했다. 나는 지난 분기에는 내 삶을 프로토타이핑하는데 사용했다. 이 때 컨설팅과 강의를 해봤는데 둘 다 재미 있었다. 그러나 컨설팅은 내가 감당할 수있는 것보다 더 많은 스트레스를 가져 왔지만 강의는 잘 되었다. 나는 또한 내 웰빙에 중요한 두 가지, 즉 달리기와 쓰기를 발견했다. 정신적 건강으로는 글쓰기 및 신체적 건강으로는 달리기가 큰 영향을 미쳤다. 나는 이제 행복한 밤이 어떤 모습인지에 대한 좋은 가설을 얻기도 했다.
그래서 나는 가르치고, 쓰고, 달리기를 해야했다.
그 시작점에서 나는 나를 목표로 이끌 수있는 많은 아이디어를 생각해 냈다. Dschool에서 찾아보고, General Assembly에서 더 많은 작업을 탐색하고, 함께 책을 쓰자는 제안을 받기도 했다. 최소한 돈이 쓰지 않고 발표를 할 방법을 찾았다. 나는 한덩어리로 구성된 계획(monolithic product plan) (어쨌든 거짓말 인 경향이 있음)을 피하고 대신 자주 평가할 수있는 프로젝트 모음을 만드는데 팬이 되었다. 그래서 저는 제가 시도 할 수있는 활동들을 모아서 순서를 정했다.
주간 보고: 그런 다음 대부분의 사람들이 이야기하지 않는 부분 (또는 가치)를 설정한다.
나는 내 경력을 쌓으면서 주간 보고서를 많이 작성해야했고, 이 보고서는 주로 나는 작성하고 싶지 않았고 상사가 읽고 싶지 않은 보통은 성가시고 지루한 잡무 목록이었다. 그러나 Zynga에서 우리는 이를 멋지게 만드는 방법을 배웠다. 그것은 중요한 변화를 가져온 것들을 추적하고 보고하는 것과 관련이있었다. 그 이후로 시간이 지남에 따라 적절히 조정하면서 컨설팅할 때에도 사용했다.
주간 보고 이메일 형식은 스탠드 업과 유사하다. 지난 주 한일, 다음 주 할일, 어려움이 있는 일을 이야기 하는 것이다. 이메일을 수신하는 사람이 꼭 알아야 할 사항인 "노트" 부분을 추가했다. 또한 각 항목에는 P1 (이번 주에 수행), P2 (가능한 경우 이번 주에 수행) 또는 P3 (고려)의 우선 순위가 있다.
각 섹션에는 3개의 P1 만 있을 수 있다. 두 개의 P2도 가질 수 있다. 아마도 P3도 있을 수 있다. 나는 그들을 상사에게 보내는 것을 아주 즐겼다. 그것은 우리의 우선 순위가 촘촘하게 목표와 맞춰 졌는지 확인했다. 내가 P1을 주었는데 / 상사가 P2라고 생각했다면, 각자가 작업의 긴급성에 대해 다르게 생각하는 이유에 대해 대화를 나눌 수 있었다.
P1은 중요한 것이다. 나는 등급 메기기(stack rank)의 엄청난 팬이다. 나는 모든 것에 순위를 매긴다. 이 방법은 명확성을 제공한다. 이것은 당신을 방종에서 보호한다. 이 것은 당신이 당신의 가치를 검토하게 만든다.
보고서의 지난 주 섹션에는 동의한 우선 순위와 완료 여부가 나열된다. 그렇지 않았다면 왜 안료 되지 않았는가? 무엇이 당신을 엉망으로 만드는 패턴인지 살펴 볼 수 있다.
어려움이 있는 일은 도움이 필요한 것이다. 속도를 늦추는 것들은 스스로 제거 할 수 없다.
자신이 해결하지 못하는 어려운 일을 직접 제거 할 수 있다면 그냥 제거하라. 이 보고서는 변명을위한 것이 아니라 실행을위한 것이다.
내 코치는 상사 대신 주간 보고 이메일 수신에 동의했다. 누군가에게 정직하게이메일을 보내는 것이 좋다.
나는 이미 이 실천에서 배우고 있다. 나는 책 제안이 얼마나 많은 작업이 필요로 하는지를 과소 평가했다는 것을 인정하고 목표를 책 쓰기에서 책의 개요 쓰기로 나의 목표를 바꾸었다. 날씨가 내 운동 일정에 영향을 미칠 것이라는 것을 깨달았고 이 부분에 대해 유연해 져야 했다. 가끔은 내가 바라는 것보다 더 많이 지키지 못한다는 것을 인정해야했고 그것을 이겨낼 방법을 찾아야 했다.
따라서 우리가 목표를 유지할 방법을 찾으려고 노력할 때 OKR을 고려하십시오. 연말의 큰 소원보다는 함께 할 수있는 계획은 어떠한가?
크리스티나 워드케가 Personal OKR을 하면서 참고할 수 있는 팁들이 있다. 분기별로 Objective를 세우고 Key Results들을 정의 한다. 이를 주간으로 진행하면서 마치 일을 하며 상사에게 보고하듯이 코치에게 조언을 받으면 실행하는 실제 방법에 대해 설명한다.
[2]크리스티나 워드케(지은이),박수성 (옮긴이), "구글이 목표를 달성하는 방식 OKR", 한국경제신문 2018-11-23 원제 : Radical Focus: Achieving Your Most Important Goals with Objectives and Key Results (2016년)
Cleann Architecture[1]에서 컴포넌트는 배포 단위를 나타낸다. 즉, "시스템의 구성 요소"로 배포할 수 있는 "가장 작은 단위"로서, 자바의 경우 jar 파일이 루비에서는 gem파일 그리고, 닷넷에서는 DLL이 그것이라고 할 수 있다. 컴포넌트가 마지막에 어떤 형태로 배포되든, 잘 설계된 컴포넌트라면 반드시 독립적으로 배포 가능한, 따라서 독립적으로 개발 가능한 능력을 갖춰야 한다. 즉, 팀이 개발하는 독립된 단위가 컴포넌트여야 한다.
이전에 이야기한 SOLID원칙이 벽과 방에 벽돌을 배치하는 방법을 알려 준다면, 여기서 이야기 하는 컴포넌트 원칙은 빌딩에 방을 배치하는 방법을 설명해 주는 것이라 생각하면 된다고 한다.
주로 응집도(Cohesion)과 결합도 혹은 의존도(Coupling)에 대해서 논의 한다. 응집도는 관련된 것들이 모여 있도록 하는 법칙이다. 반대로 의존도는 관련 없는 것들을 분리하는 것이라고 볼 수 있다. 컴포넌트들이 관련 없을 수 없기 때문에 효과적으로 의존하도록 만든는 것이라 볼 수 있다.
재사용/릴리즈 등가 원칙은 너무 당연해 보인다. 소프트웨어 컴포넌트가 릴리스 절차를 통해 추척 관리되지 않거나 릴리스 번호가 부여되지 않는다면 해당 컴포넌트를 재사용하고 싶어도 할 수도 없고, 하지도 않을 것이다.
이 원칙을 소프트웨어 설계와 아키텍처 관점에서 보면 단일 컴포넌트는 응집성 높은 클래스와 모듈들로 구성되어야 함을 뜻한다. 단순히 뒤죽박죽 임의로 선택된 클래스와 모듈로 구성되어서는 안 된다. 컴포넌트를 구성하는 모든 모듈은 서로 공유하는 중요한 테마나 목적이 있어야 한다.
이 조언만으로는 클래스와 모듈을 단일 컴포넌트로 묶는 방법을 제대로 설명하기 힘들기에 이 조언이 약하다고 하는 것이다. 그렇더라도 이 원칙 자체는 중요하다. 이 원칙을 어기면 쉽게 발견할 수 있기 때문이다.
공통 폐쇄 원칙 (Common Closure Principle, CCP)
CCP는 "동일한 이유로 동일한 시점에 변경되는 클래스를 같은 컴포넌트로 묶어라. 서로 다른 시점에 다른 이유로 변경되는 클래스는 다른 컴포넌트로 분리하라."라는 원칙이다.
이 원칙은 단일 책임 원칙(SRP)을 컴포넌트 관점에서 다시 쓴 것이다. 공동 폐쇄 원칙(CCP)에서도 마찬가지로 단일 컴포넌트(Component)는 변경이 이유가 여러 개 있어서는 안 된다고 말한다.
대다수의 애플리케이션에서 유지보수성(maintainability)은 재사용성보다 훨씬 중요하다. 애플리케이션에서 코드가 반드시 변경되어야 한다면, 이러한 변경이 여러 컴포넌트 도처에 분산되어 발생하기보다는, 차라리 변경 모두가 단일 컴포넌트에서 발생하는 편이 낫다. CCP는 같은 이유로 변경될 가능성이 있는 클래스는 모두 한곳으로 묶을 것을 권한다.
이 원칙은 개방 폐쇄 원칙(OCP)과도 밀접하게 관련되어 있다. 실제로 CCP에서 말하는 '폐쇄closure'는 OCP에서 말하는 '폐쇄closure'와 그 뜻이 같다. OCP에서는 클래스아 변경에는 닿혀 있고 확장에는 열려 있어야 한다고 말한다. 100%완전한 폐쇄란 불가능하므로 전략적으로 폐쇄해야 한다.
공통 재사용 원칙(Common Reuse Principle, CRP)
CRP는 "컴포넌트 사용자들은 필요하지 않은 것에 의존하게 강요하지 말라"라는 원칙이다.
공통 재사용 원칙(CRP)도 클래스와 모듈을 어느 컴포넌트에 위치시킬지 결정할 때 도움되는 원칙이다. CRP에서는 같이 재사용되는 경향이 있는 클래스와 모듈들은 같은 컴포넌트에 포함해야 한다고 말한다.
간단한 사례로 컨테이너 (Container) 클래스와 해당 클래스의 이터레이터(Iterator) 클래스를 들 수 있다. 이들 클래스는 서로 강하게 결합되어 있기 때문에 함께 재사용 된다. 따라서 이들 클래스는 반드시 동일한 컴포넌트에 위치해야 한다. 따라서 CRP는 어떤 클래스를 한데 묶어도 되는지 보다는, 어떤 크래스를 한데 묶어서는 안되는지에 대해서 훨씬 더 많은 것을 이야기 한다. CRP는 강하게 겨합되지 않은 클래스들을 동일한 컴포넌트에 위치시켜서는 안 된다고 말한다.
CRP는 SOLID의 인터페이스 분리 원칙(ISP)의 포괄적인 버전이라 할 수 있다. ISP는 사용하지 않은 메서드가 있는 클래스에 의존하지 말라고 조언한다. CRP는 사용하지 않는 클래스를 가진 컴포넌트에 의존하지 말라고 조언한다.
컴포넌트 응집도에 대한 균형 다이어그램
아마도 응집도에 관한 세원칙이 서로 상충된다. REP와 CCP는 포함(Inclusive)원칙이다. 즉, 두 원칙은 컴포넌트를 더욱 크게 만든다. CRP는 배제(exclusive)원칙이며, 컴포넌트를 더욱 작게 만든다.
컴포넌트응집도(Component Cohesion)[1]
원칙에 반대 위치에 있는 Edge에는 원칙을 따르지 않을 때 감수해야 하는 비용을 나타낸다. 즉, 위에 그림에서 오로지 REP와 CRP에만 중점을 두면, 사소한 변경이 생겼을 때 너무 많은 컴포넌트에 영향을 미친다. 반대로 CCP와 REP에만 과도하게집중하면 불필요한 릴리즈가 너무 빈번해 진다.
뛰어난 아키텍트라면 이 균형 삼각형애서 개발팀이 현재 관심을 기울이는 부분을 충족시키는 위치를 찾아야 하며 또한 시간이 흐르면서 개발팀이 주의를 기울이는 부분 역시 변한다는 사실도 이해하고 있어야 한다. 일반적으로 프로젝트는 삼각형의 오른쪽에서 시작하는 편이며, 이대는 오직 재사용성만 희생하면 된다. 프로젝트가 성숙하고,, 그 프로젝트로 부터 파생된 또 다른 프로젝트가 시작되면 프로젝트는 삼각혀엥서 점차 왼쪽으로 이동해 간다.
컴포넌트 결합
의존성 비순환 원칙(Acyclic Dependencies Principles, ADP)
ADP는 "컴포넌트 의존성 그래프에 순환(cycle)이 있어서는 안 된다"는 원칙이다.
숙취 증후군 the morning after syndrome'이라고 부른다. 퇴근 후, 이튿날 다른 사람의 작업으로 전혀 돌아가지 않는 경험을 말하는 것으로 많은 개발자가 동일한 소스 파일을 수정하는 환경에서 발생한다. 소수의 개발자로 구성된 상대적으로 작은 프로젝트에서는 이 증후군이 그다지 큰 문제가 되지 않는다.
이 문제의 해결책은 개발 환경을 릴리스 가능한 컴포넌트 단위로 분리하는 것이다. 컴포넌트가 새로 릴리스되어 사용할 수 있게 되면 다른 팀에서는 새 릴리스를 당장 적용할지를 결정해야 한다. 적용하지 않기로 했다면 그냥 과거 버전의 릴리스를 계속 사용한다. 이렇게 될 수 있다면, 어떤 팀도 다른 팀에 의해 좌우 되지 않는다. 특정 컴포넌트가 변경되더라도 다른 팀에 즉각 영향을 주지 않는다. 각 팀은 특정 컴포넌트가 새롭게 릴리스되면 자신의 컴포넌트를 해당 컴포넌트에 맞게 수정할 시기를 스스로 결정할 수 있다. 뿐만 아니라 통합은 작고 점진적으로 이뤄진다. 특정 시점에 모든 개발자가 한데 모여서 진행 중인 작업을 모두 통합하는 일은 사라진다.
이 절차가 성공적으로 동작하려면 컴포넌트 사이의 의존성 구조를 반드시 관리해야 한다. 의존성 구조에 순환이 있어서는 안 된다. 구조가 방향 그래프(Directed graph)이라고 하면, 컴포넌트는 정점(Vertex)에 해당하고, 의존성 관계는 방향이 있는 간선 (Directed edge)에 해당한다 볼 수 있다. 이렇게 비순환 방향 그래프(Directed Acyclic Graph, DAG)로 구조를 만들면 문제가 해결 된다. 이렇게 할 수 있는 두 가지 방법은 아래와 같다.
의존성 역전 원칙(DIP)을 적용한다.
Entities와 Authorizer가모두 의존하는 새로운 컴포넌트를 만든다.
안정된 의존성 원칙 (Stable Dependencies Principles, SDP)
SDP는 "안정성의 방향으로(더 안정된 쪽에) 의존하라"라는 원칙이다.
하나의 모듈에 누군가가 의존성을 매달아 버리면 이 모듈은 변경하기 어려워진다. 이 모듈에서는 단 한 줄의 코드도 변경되지 않았지만, 어느 순간 갑자기 해당 모듈을 변경하는 일이 상당히 도전적인 일이 되어 버리는 것이다.
안전성(Stability)이란 무엇인가? '쉽게 움직이지 않는'이라고 정의할 수 있다. 아래 그림5의 X는 안정된 컴포넌트다. 세 컴포넌트가 X에 의존하며, 따라서 X 컴포넌트는 변경하지 말아야 할 이유가 세 가지나 되기 때문이다. 이 경우 X는 세 컴포넌트를 책임진다(Responsible)라고 말한다. 반대로 X는 어디에도 의존하지 않으므로 X가 변경되도록 만들 수 있는 외적인 영향이 전혀 없다. 이 경우 X는 독립적이다(Independent)라고 말한다.
아래 그림의 Y는 상당히 불안정한 컴포넌트다. 어떤 컴포넌트도 Y에 의존하지 않으므로 Y는 책임성이 없다고 말할 수 있다. 또한 Y는 세 개의 컴포넌트에 의존하므로 변경이 발생할 수 있는 외부 요인이 세 가지다. 이 경우는 Y는 의존적이라고 말한다.
안정성(Stability)[1]
이와 같은 정의에서 안정성 지표는 아래와 같이 정의 될 수 있다.
Fan-in 안으로 들어오는 의존성
Fan-out 바깥으로 나가는 의존성
I(불안정성):I = Fan-out / (Fan-in + Fan-out) 이 지표는 [0,1] 범위의 값을 갖는다. 1이면 최고로 불안정한 상태이고, 0이면 최고로 안정된 상태
안정된 추상화 원칙(Stable Abstractions Principle, SAP)
SAP는 "컴포넌트 안정된 정도만큼만 추상화되어야 한다"라는 원칙이다.
안정된 추상화 원칙(Stable Abstractions Principle, SAP)은 안정성(Stability)과 추상화 정도(Abstractness) 사이의 관계가 정의 한다. 이 원칙은 한편으로는 안정된 컴포넌트는 추상 컴포넌트여야 하며, 이를 통해 안정성이 컴포넌트를 확장하는 일을 방해해서는 안 된다고 말한다.
추상화 정도 측정하기 위한 A지표는 컴포넌트의 추상화 정도를 측정한 값으로 다음과 같이 정의 될 수 있다.
Nc: 컴포넌트의 클래스 개수
Na: 컴포넌트의 추상 클래스와 인터페이스의 개수
A: 추상화 정도. A=Na/Nc" A가 0이면 컴포넌트에는 추상 클래스가 하나도 없다는 뜻이다. A가 1이면 컴포넌트는 오로지 추상 클래스만을 포함한다는 뜻이다.
주계열(the main sequence)
이제 안정성(I)과 추상화 정도(A) 사이의 관계를 정의해야 할 때가 왔다. 우선 고통의 구역과 쓸모 없는 구역을 살펴 보고, 주 계열(The main sequence)에 대해서 살펴 보자.
고통의 구역(Zone of Pain), (0,0) 주변 구역에 위치한 컴포넌트를 살펴보자. 이 컴포넌트는 매우 안정적이며 구체적이다. 일부 소프트웨어 엔티티는 고통의 구역에 위치하곤 한다. 데이터베이스 스키마가 한 예다. 데이터베이스 스키마는 변동성이 높기로 악명이 높으며, 극단적으로 구체적이며, 많은 컴포넌트가 여기에 의존한다. 유틸리티 라이브러리로 실제로는 변동성이 거의 없다. 변동성이 없는 컴포넌트는 (0,0)구역에 위치했더라도 해롭지 않다.
쓸모없는 구역(Zone of Uselessness), (1, 1) 주변의 컴포넌트를 생각해 보자. 이 영역도 바람직하지 않은데, 여기위치한 컴포넌트는 최고로 추상적이지만, 누구도 그 컴포넌트에 의존하지 않기 때문이다. 이러한 컴포넌트는 아무도 쓰지 않으므로 쓸모가 없다.
일반적으로 변동성이 큰 컴포넌트 대부분은 두 배제 구역으로부터 가능한 한 멀리 떨어뜨려야 한다. 각 배제 구역으로부터 최대한 멀리 떨어진 점의 궤적은 (1,0)과 (0,1)을 잇는 선분이다. 나는 이 선분을 주계열(Main Sequence)이라고 부른다.
여기서, 주계열과의 거리, 세 번째 지표가도출된다. 컴포넌트가 주계열 바로 위에 또는 가까이 있는 것이 바람직하다면 이 같은 이상적인 상태로 부터 컴포넌트가 얼마나 떨어져 있는지 특정하는 지표를 만들어 볼 수 있다.
D: 거리. = |A+I-1| 유효범위는 [0,1]
주 계열(Main Sequence)와 컴포넌트 산점도[1]
결론
Clearn Architecture에서 설명하는 응집도(Cohesion)와 관련된 REP, CRP, CCP원칙에 대해서 살펴 보았고, 응집도 균현 다이어그램을 살펴 보았다. 그리고, 결합도와 관련된 ADP에서는 어떻게 순환을 끊을 수 있는지 살펴 보았고, SDP와 SAP 원칙에서 분안정성(Instability)와 추상화 정도(Abstractness)의 관계를 통해서 주 계열(Main sequence)를 살펴 보았다.
참고문헌
[1] 로버트 C. 마틴 저, "클린 아키텍처 소프트웨어 구조와 설계의 원칙" 인사이트(insight) 2019년 08월 20일, 송준이 역
Clearn Architecture[1]에서는 좋은 소프트웨어 시스템은 깔끔한 코드(Clean Code)로 부터 시작한다고 이야기 한다. 이러한 코드들이 모여서 요소(Element)가 되는데 이를 건물에 보면 벽돌로 볼 수 있다. 좋은 벽돌로 좋은 아키텍처를 정의하는 원칙이 필요한데 그게 바로 SOLID라고 이야기 한다. 즉, SOLID 원칙은 함수와 데이터구조를 클래스로 배치하는 방법, 그리고 이들 클래스를 서로 결합하는 방법을 설명한다. 사실 SOLID 원칙은 "Design Pattern 첫 번째: Object Oriented Principles"[2]에서 Object Oriented Programming의 설계 원칙 중 하나로 다루었지만 여기서는 조금 더 다른 관점에서 다룬다.
원칙의 목적은 "중간 수준"의 소프트웨어 구조가 아래와 같도록 만드는데 있다.
변경에 유연하다.
이해하기 쉽다.
많은 소프트웨어 시스템에 사용될 수 있는 컴포넌트의 기반이 된다.
S.O.L.I.D는 아래 다섯가지 원칙의 약자를 모은 것이다.
Single Responsibility Principle
Open Close Principle
Liskov Substitution Principle
Interface Seggregation Principle
Dependency Inversion Principle
책에서는 2004년 무렵, 레거시 코드 활용 전략의 저자 마이클 페더스(Michael Feathers)가 기존에 있던 원칙을 재배열하여 각 원칙의 첫 번째 글자들로 SOLID라는 단어를 만들었다고 한다. 각 원칙을 하나씩 살펴 보자.
단일 책임 원칙 (Single Responsibility Principle)
객체 지향 프로그래밍(Object Oriented Programming)에서 하나의 객체는 하나의 책임을 가진다는 원칙이다.
하나의 책임이라는 부분은 사실 모호한다. 어떤 클래스가 가지는 책임이 하나라는 것은 한가지 일만 한다고 하기에는 1차원 적인 것이 있다. 이 책에서는 최종 버전으로 "하나의 모듈은 하나의, 오직 하나의 액터에 대해서만 책임져야 한다."라고 이야기 한다. 모듈이 하나의 객체 혹은 소스 파일로 볼 수 있다. 여기서 액터는 개발자/팀이라고 볼 수 있다. 그렇다면, 하나의 소스 파일은 개발자/팀이 책임 져야 한다는 것이다. 분리된 팀이 하나의 소스 파일을 건드린다면 팀을 합치거나 혹은 파일을 분리해야 한다는 이야기로 이해할 수 있다.
책[1]의 예를 살펴 보자.
Employee Class [1]
calculatePay() 매서드는 회계팀에서 기능을 정의하며, CFO 보고를 위해 사용한다.
reportHours() 매서드는 인사팀에서 기능을 정의하고 사용하며, COO 보고를 위해 사용된다.
save 매서드는 데이터베이스 관리자(DBA)가 기능을 정의하고, CTO 보고를 위해 사용된다.
즉, 서로 다른 액터가 의존하는 경우는 많이 발생한다. SRP에 따르자면, 이 코드는 분리하라고 하는 것이다. 어떻게 분리할 수 있을까? 최종적으로는 2가지가 가능해 보인다.
이 해결책은 개발자가 세가지클래스를 인스턴스화하고 추적해야 한다는게 단점이다. 이럴 때, 흔히 쓰는 기법으로 파사드(Facade) 패턴이 있다. 아래 그림과 같이, EmployeeFacade에 코드는 거의 없다. 이 클래스는 세 클래스의 객체를생성하고, 요청된 메서드를 가지고 객체로 위임하는 일을 책임진다. 이렇기 때문에, Facade는 Architectural Composition이라고도 한다.
Facade Pattern[1]
Employee Data를 CFO에서 담당한다고 하면 Employee Facade Class로 가져올 수 있다면 구조는 조금 더 단순화 될 수 있다. 아래 구조가 최종 구조라고 하면, CFO는 Employee Class를 담당하고, COO는 HourReporter Class를 담당하며, CTO는 EmployeeSaver Class를 각각 담당하여 개발을 진행하면 SRP가 잘 유지되며 개발될 수 있다고 볼 수 있다. 이처럼 조직의 구조도 Software의 구조에 영향을 미친다.
Facade Pattern 두 번째[2]
개방-폐쇄 원칙 (Open Close Principle OCP)
개방-폐쇄 원칙(OCP)이라는 용어는 1988년 버트란드 마이어(Bertrand Meyer)가 만들었는데, 소프트웨어 개체(Artifact)는 확장에는 열려 있어야 하고(Open to Extension) 변경에는 닫혀 있어야 한다(Close to Modification)라는 원칙이다. 즉, 객체의 행위는 확장할 수 있어야 하지만, 이 때 개체를 변경해서는 안된다. 어찌 보면 모순 같은 이야기는 매우 중요한 원칙이기도 하다.
책에서는 여러 번 이야기 하지만, 변경이 되지 많아야 할 곳과 변경이 되는 것을 분리하고 변경이 되는 곳이 변경되지 않는 것에 종속되도록(Dependent)하도록 해야 한다는 것이다. 그리고, 이 변경 되는 쪽을 확장하는 쪽으로 쓰고 변경되지 않도록 하는 쪽은 한 곳으로 모아 두어야 한다는 원칙이다.
어떻게 이를 획득할 수 있을까? 책에서의 제무제표 웹 시스템에서는 그러한 예를 많이 보유하고 있다.
재무 제표 웹 시스템[1]
일반적인 방향성 제어의 방법에서는 위의 예에서 FinancialDataGateway 인터페이스는 FinacialReportGenerator와 FinancialDataMapper 사이에 위치하는데, 이는 의존성을 역전시키기 위해서이다. 만일 이러한 DataGateway가 없다면 FinancailReportGenerator Class는 Database Component에 의존하게 된다. 즉, Database가 SQL이었다고 다른 Database로 변경된다면 영향을 받고 변경될 가능성이 생기게 된다. 하지만 Database들이 거꾸로 FinancialDataGateway가 존재함으로서 Database들은 여기에 의존하게 되면서 의존성이 역전되게 된다. FianancialReportPresenter 인터페이스와 2개의 View 인터페이스도같은 목적을 가진다.
정보은닉 차원에서 OCP도 위의 예에서 살펴 볼 수 있다. FainacialReportRequester 인터페이스는 방향성 제어와는 달리, FinancialReportController가 Ineractor 내부에 대해 너무 많이 알지 못하도록 막기 위해서 존재한다. 즉, 의존 관계를 바꾸지는 않지만 의존하는 Class의 의존도를 제한하고 변경이 있을 때에도 인터페이스에 한정하여 의존성을 가지도록 하여 OCP를 유지할 수 있다. 즉, 여러 모듈의 의존도가 있는 모듈인 경우 각 Interafce를 분리하여 정보은닉을 하면서 OCP 의 효과를 획득하는 것이라 할 수 있다.
리스코프 치환 원칙(Liskov Substituion Priniciple)
1988년 바바라 리스코프(Barbara Liskov)는 하위 타입(Subtype)을 아래와 같이 정의했다.
S 타입의 객체 o1, T 타입의 객체 o2일 경우, T타입을 이용해서 정의한 모든 프로그램 P에서 o2의 자리에 o2을 치환하더라도 P의 행위가 변하지 않는다면, S는 T의 하위 타입이다.
LSP 예제
이 원칙은 일반적으로 OOP에서 상속을 사용하도록 가이드 한다. 위의 예가 바로 그것인데, Billing 애플리케이션의 행위가 License 하위 타입 중 무엇을 사용하는지에 전혀 의존하지 않기 때문이다. 이들 하위 타입은 모두 License 타입을 치환할 수 있다. 이를 Liskov Substitution Principle LSP라고 한다.
정사각형/직사각형 문제는 LSP에서 발생될 수 있는문제를 설명한다. Square는 Rectangle의 하위 타입으로는 적합하지 않은데, Rectangle의 높이와 너비는 서로 독립적 변경이다. 하지만, Squarue이 높이와 너비는 반드시 함께 변경되기 때문이다. 이런 형태의 LSP 위반을 막기 위한 유일한 방법은 (if문 등을 이용해서) Rectangle이 실제로는 Square인지 검사하는 매커니즘을 User에 추가하는 것이다. 하지만 이렇게 하면 User의 행위가 사용하는 타입에 의존하게 되므로 결국 타입을 서로 치환할 수 없게 된다. 다시 말하자면, 개념적으로는 LSP라 생각하기 쉽지만 이렇게 LSP를 적용하는데는 적당하지 않다.
Square LSP 위반 사례[1]
객체 지향이 혁명처럼 등장한 초창기에는 앞서 본 것 처럼 LSP는 상속을 사용하도록 가이드하는 방법 정도로 간주 되었다. 하지만, LSP는 인터페이스와 구현체에도 적용되는 더 광범위한 소프트웨어 설계 원칙으로 변모하였다.
인터페이스 분리 원칙(Interface Segregation Principle, ISP)
아래 왼쪽 그림 기술된 상황에서,다수의 사용자가 OPS 클래스의 오퍼레이션을 사용한다. User1은 오직 op1을 User2는 op2만을 User3는 op3만을 사용한다고 가정해 보자. 이러한 문제는 아래 그림 오른쪽에서 보는 것처럼 오프레이션을 인터페이스 단위로 분리하여 해결할 수 있다.
Interface Segregation Principle [1]
정적타입 언어는 소스코드에 '포함된 included'선언문으로 인해 소스 코드 의존성이 발생한다. 루비나 파이썬과 같은 동적 타입 언어서는 소스코드에 이러한 선언문이 존재하지 않는다. 대신 런타임에 추론이 발생한다. 동적 타입 언어를 사용하면 유연하며 결합도가 낮은 시스템을 만들 수 있는 이유는 바로 이때문이다.이러한 사실로 인해 ISP를 아키텍처가 아니라, 언어와 관련된 문제라고 결론내릴 여지가 있다.
일반적으로 필요 이상으로 많은 걸 포함하는 모듈에 의존하는 것은 해로운 일이다. 고수준인 아키텍처 수준에서도 마찬가지 상황이다.
의존성 역전 원칙 (Dependency Inversion Principle)
의존성 역전 원칙(DIP)에서 말하는 '유연성이 극대화된 시스템'이란 소스 코드 의존성이 추상(Abstraction)에 의존하며 구체(Concretion)에는 의존하지 않는 시스템이다. use, import, include 구문은 오직 인터페이스나 추상 클래스 같은 추상적인 선언만 참조해야 한다는 뜻이다. 구체적인 대상에는 절대로 의존해서는 안 된다.
우리가 의존하지 않도록 피하고자 하는 것은 바로 변동성이 큰(Volatile) 구체적인 요소다. 그리고 이 구체적인 요소는 우리가 열심히 개발하는 중이라 자주 변경될 수 밖에 없는 모듈들이다.
실제로 뛰어난 소프트웨어 설계자와 아키텍트라면 인터페이스의 변동성을 낮추기 위해 애쓴다. 인터페이스를 변경하지 않고도 구현체에 기능을 추가할 수 있는 방법을 찾기 위해 노력한다. 다음과 같은 매우 구체적인 코딩 실천법이 있다. 사실 이것이 DIP를 다시 쓴것과 같다.
변동성이 큰 구체 클래스(Concrete Class)를 참조하지 말라. (Refer)
변동성이 큰 구체 클래스(Concrete Class)로 부터 파생하지 말라 (Derive)
구체함수를 오버라이드하지 말라. 대체로 구체 함수는 소스 코드 의존성을 필요로 한다. 따라서 구체 함수를 오버라이드하면 이러한 의존성을 제거할 수 없게 되며, 실제로는 그 의존성을 상속하게 된다.
구체적이며 변동성이 크다면 절대로 그 이름을 언급하지 말라
아래 그림에서 곡선은 아키텍처 경계를 뜻한다. 이 곡선은 구체적인 것들로부터 추상적인 것들을 분리한다. 소스 코드 의존성은 해당 곡선과 교차할 때 모두 한 방향, 즉, 추상적인 쪽으로 향한다. 제어흐름은 소스 코드 의존성과는 정반대 방향으로 곡선을 가로지른다는 점에 주목하자. 다시 말해 소스 코드 의존성은 제어흐름과는 반대 방향으로 역전된다. 이러한 이류로 이 원칙을 의존성 역전(Dependency Inersion)이라고 부른다.
Dependency Inversion Principle[1]
위 그림의 구체 컴포넌트에는 구체적인 의존성이 하나 있고, 따라서 DIP에 위배된다. 이는 일반적인 일이다. DIP 위배를 모두 없앨 수는 없다. 하지만 DIP를 위배하는 클래스들은 적은 수의 구체 컴포넌트 내부로 모을 수 있고, 이를 통해 시스템의 나머지 부분과는 분리할 수 있다.
결론
S.O.L.I.D는 Single Responsibility Principle, Open Close Principle, Liskov Substitution Principle, Interface Seggregation Principle, Dependency Inversion Principle의 앞글자를 딴 것이다. 원칙 하나씩 따져 보았지만, 서로 서로 관련되어 있는 것을 살펴 볼 수가 있다. 이러한 원칙은 컴포넌트 혹은 아키텍처로 확장될 수 있다. 또한, 이러한 원칙은 Design Pattern의 각 패턴의 기본 원칙으로 각 패턴을 상세히 설명하는데도 사용된다.
참고 도서
[1] 로버트 C. 마틴 저, "클린 아키텍처 소프트웨어 구조와 설계의 원칙" 인사이트(insight) 2019년 08월 20일, 송준이 역