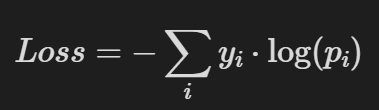이번 글에서는 “LLM을 실제 서비스로 만들기 위한 설계 방법”을 다룬다.
핵심은 세 가지다:
- LLM 아키텍처 설계
- 데이터 설계 (가장 중요)
- Fine-tuning 전략 (SFT + QLoRA)
1. LLM 시스템은 하나의 모델이 아니다
많은 사람들이 LLM 시스템을 이렇게 생각한다:
“좋은 모델 하나 쓰면 끝”
하지만 실제로는 전혀 다르다.
실무에서는 보통 다음과 같은 구조를 가진다:
[User Request]
↓
[Router / Parser] (작은 모델)
↓
[Main LLM] (중간 모델)
↓
[Reasoning LLM] (필요 시 fallback)
↓
[Judge / Evaluator]핵심은 이것이다:
“큰 모델 하나로 해결하지 말고 역할을 분리하라”
2. 왜 모델을 나눠야 하는가
이 구조는 단순한 기술적 선택이 아니다. 비용 / 성능 / 안정성의 균형 문제다.
역할별 특징
- Router (1B~4B)
- intent 분류
- tool 선택
- JSON 구조 강제
- → 빠르고 싸야 한다
- Main LLM (7B~13B)
- 일반 QA
- RAG 응답
- 대화 처리
- → 대부분의 요청 처리
- Reasoning LLM (30B+)
- 복잡한 추론
- 멀티 스텝 문제
- → fallback 전용
- Judge
- 품질 평가
- A/B 테스트
이 구조는 결국 이렇게 요약된다: “모든 요청을 비싼 모델로 처리하지 않는다”
3. 데이터가 성능의 80%를 결정한다
모델보다 중요한 것이 있다. 바로 데이터이다. 특히 SFT에서는 더 그렇다.
4. Schema First: 먼저 형식을 고정하라
가장 인상 깊었던 개념이다.
모델은 “의미”보다 “형식”을 먼저 학습한다
예를 들어:
- JSON 구조
- 필드 이름
- 응답 포맷
이게 흔들리면? downstream 시스템 전체가 깨진다
그래서 필요한 것
- Key 구조 고정 (intent, slots, status 등)
- 값 범위 정의 (ready / need_clarification 등)
- null vs "" 규칙 통일
- 필수 필드 강제
결론:
학습 전에 schema를 먼저 설계하라
5. 좋은 데이터는 “틀리는 데이터”다
이건 거의 철학에 가깝다. 많은 사람들이 이렇게 데이터 만든다:
쉬운 데이터 위주가 아니다.
결과:
- 과적합
- 실전 성능 붕괴
좋은 데이터의 특징
모델이 틀리는 케이스 중심
- Ambiguous (모호한 요청)
- 정보 부족
- 조건 충돌
- 비정상 요청 (jailbreak 등)
예:
- “전화해봐” → 누구에게?
- “새벽 3시에 예약해” → 현실적으로 가능한가?
핵심:
“좋은 데이터는 모델이 틀린 데이터다”
6. 데이터 분포 전략
추천 분포:
- Common: 60~70%
- Edge: 15~25%
- Ambiguous: 10~15%
이 구조는 중요한 의미를 가진다. 즉, 실패 영역을 중심으로 학습한다
7. 데이터는 수집이 아니라 “생성”이다
또 하나 중요한 포인트:
데이터는 모으는 것이 아니라 만들어야 한다
방법:
- 실패 케이스 수집
- 패턴 분석
- 템플릿화
- LLM으로 데이터 증강
특히 edge / ambiguous 케이스는 의도적으로 만들어야 한다
8. SFT의 본질 (오해 깨기)
많은 사람들이 SFT를 이렇게 이해한다:
“모델을 더 똑똑하게 만든다” 하지만 실제는 다르다.
SFT는 “더 많이 알게 하는 것”이 아니라
“원하는 형태로 출력하게 만드는 것”
SFT가 잘 맞는 경우
- JSON 출력 강제
- Tool calling
- 분류 / 라우팅
- 포맷 제어
즉, 패턴 학습 문제가 잘 맞는다.
9. Tool Calling은 사실 SFT 문제다
예를 보자:
{
"function_name": "get_weather_info",
"arguments": {
"location": "서울 강남구",
"current_temp": true
}
}이걸 잘 만들게 하는 방법은?
RAG가 아니라 SFT. 왜냐하면:
- 지식 문제가 아니라
- 형식 문제이기 때문
10. Fine-tuning 전략: Full vs LoRA vs QLoRA
현실적인 선택은 세 가지다:
| 방식 | 특징 |
|---|---|
| Full FT | 성능 좋지만 매우 비쌈 |
| LoRA | 일부만 학습 (효율적) |
| QLoRA | 4-bit로 더 가볍게 |
핵심 차이
- Full FT → 전체 weight 학습
- LoRA → 변화량만 학습
- QLoRA → 양자화 + LoRA
QLoRA의 의미:
작은 GPU로 큰 모델을 학습 가능
11. 메모리의 본질
모델은 결국 숫자다.
예:
- 7B 모델
- FP16
- 약 14GB 필요
그래서 등장한 것이 Quantization (4-bit 등) 이다.
12. Unsloth: 실무 최적화 도구
흥미로운 포인트 하나: Unsloth는 알고리즘이 아니다.
👉 엔지니어링 최적화
- VRAM 절감
- 속도 향상 (약 2배)
- Colab에서도 가능
핵심:
“수학은 그대로, 실행만 빠르게”
13. 중요한 디테일: Tokenizer & Special Token
이건 많이 놓치는 부분이다. 같은 문장이라도:
- 모델마다 토큰 분리 다름
- special token 다름
- chat template 다름
결과:
같은 입력인데 다른 의미로 해석됨
그래서 반드시: apply_chat_template() 사용
14. 결론: LLM 시스템 설계의 본질
이 모든 내용을 한 줄로 요약하면:
LLM 시스템은 “모델”이 아니라
데이터 + 구조 + 전략의 조합이다
핵심 정리
- 모델 하나로 해결하지 말 것
- 데이터가 성능을 결정한다
- SFT는 “형식 제어”다
- RAG는 “지식 보완”이다
- 실패 케이스가 가장 중요하다
마무리
이번 교육을 통해 가장 크게 바뀐 생각은 이것이다:
“LLM을 잘 쓰는 사람은 모델을 고르는 사람이 아니라
문제를 구조적으로 설계하는 사람이다”
필요하다면 다음 단계로:
- 실제 서비스 아키텍처 설계 (AdviceGen 적용)
- RAG + SFT 하이브리드 설계
- 비용 최적화 전략
도 이어서 정리해볼 수 있다.
'Machine Learning' 카테고리의 다른 글
| LLM은 왜 틀릴까? — 그리고 RAG vs SFT, 언제 무엇을 써야 하는가 (0) | 2026.04.22 |
|---|---|
| RAG 노코드 Dify로 맞춤형 챗봇 만들기 2/2 (0) | 2025.12.11 |
| RAG 노코드 Dify로 맞춤형 챗봇 만들기 1/2 (0) | 2025.12.10 |
| AI Coding Tools 비교 (0) | 2025.09.27 |
| Scale의 법칙과 GPT-5: 멀티코어처럼 진화하는 AI (8) | 2025.08.12 |