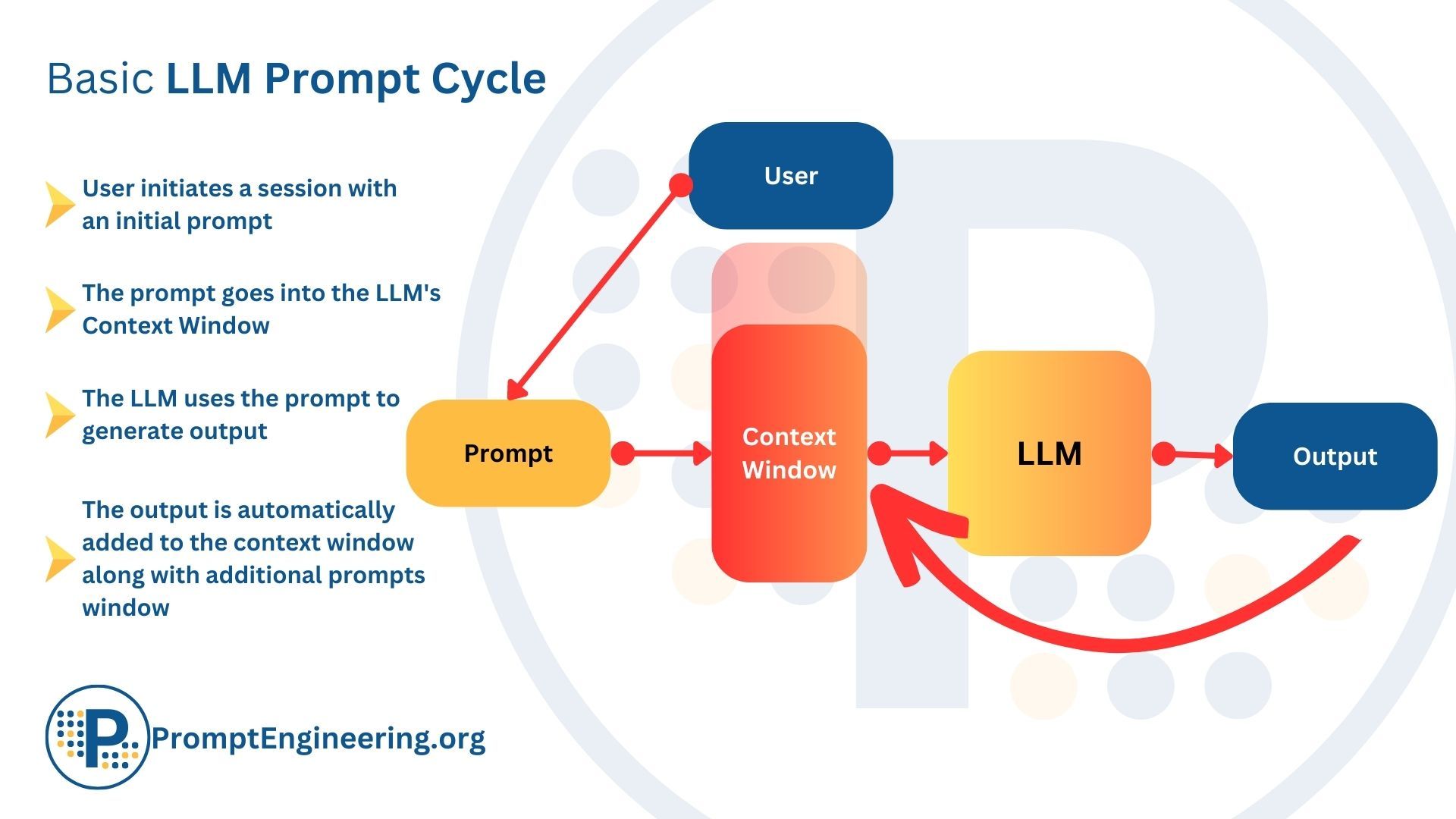
[1]에서도 다루었지만, 미리 트레이닝을 해야 하는 Machine Learning의 한 종류인 LLM도 동일한 특징을 가지고 있다. ChatGPT4o의 경우도 현재 23년 10월까지 업데이트 되어 있다고 한다. 이 부분의 한계를 극복하기 위한 것이 Retrieval Augmented Generation (RAG)이다. 이 부분은 추가된 정보를 제공해서 이를 기반으로 동작하게 하는 것이다. 이 동작을 이해하기 위한 몇 가지 개념이 있는데 임베딩 모델(Embedding Model), 벡터 데이터베이스(Vector Database)와 같은 개념이 있다. 이 부분에 대해서는 간단하게 다뤄 보자.
RAG(Retrieval-Augmented Generation)는 앞에서 언급한 Foundation Model이 최신 데이터를 가지고 학습하지 못한 문제를 해결하기 위한 방법 중 하나로, LLM에 정보 검색을 결합하는 방식 또는 프로세스를 말한다. 즉, 검색된 정보를 이용해서 최신 정보와 원하는 정보를 추가하여 생성하도록 해서 신뢰성과 지식의 범위를 확장할 수 있도록 하게 한다.
이렇게 RAG를 하기 위해서 데이터를 추가 한다고 할 때, 추가된 데이터와 기존의 정보가 어떻게 관련되어 연관성이 있는지 알 수 있을까? 이를 이해하기 위해서 필요한 것이 임베딩 모델이다. 임베딩 모델은 정보를 다차원 공간의 조밀한 표현으로 캡슐화하도록 훈련된 알고리즘이다[2]. 좀 더 자세한 내용은 YouTube를 함께 보는 것도 좋다. 여기서 시각화 한 것과 같이 유사도를 vector측면에 cosine similarity를 사용하는지도 알 수 있다. 그리고, L2 distance 혹은 vector product도 사용할 수 있음도 알 수 있다. 이러한 것을 활용하여 시멘틱 서치(semantic search)가 가능해 진다.
이러한 정보를 어떻게 보관하고 사용할 것인가? 이를 위한 데이터베이스가 벡터 데이터베이스(vector database)이다[3]. 기존 데이터베이스도 위와 같은 임베딩을 저장하고 sementic search를 할 수 있지만, 저장된 모든 데이터의 embedding과 query embedding의 similarity를 연산해야 하기 때문에 너무 많은 연산을 해야 하고 느리게 결과를 가져오게 된다. 벡터 데이터 베이스는 자체적인 알고리즘으로 indexing하고 유사도 알고리즘을 조합하여 빠른 검색을 지원하므로 LLM에 RAG를 위해서는 이러한 데이터 베이스를 활용해야 한다.
결론은 [1]에서도 언급한 것처럼 LLM에 RAG이 적용되어야만 약점을 보완한 현대적인 아키텍처를 가진다고 볼 수 있다. 이 구조에는 임베딩 모델, 벡터 데이터 베이스들이 왜 연계되어 사용되는지, 그리고 왜 cosine similarity가 사용되는지 간단한 개념들이 살펴 볼 수 있다.
참고문서
[1] Large Language Model의 추상화 , https://technical-leader.tistory.com/127
[2] 텍스트용 Vertex AI 임베딩: 간편해진 LLM 그라운딩, https://cloud.google.com/blog/ko/products/ai-machine-learning/how-to-use-grounding-for-your-llms-with-text-embeddings
[3] Vector Database: 벡터 임베딩을 저장하고 검색하는 가장 효율적인 방법, https://smilegate.ai/en/2023/11/07/vector-database-%EB%B2%A1%ED%84%B0-%EC%9E%84%EB%B2%A0%EB%94%A9%EC%9D%84-%EC%A0%80%EC%9E%A5%ED%95%98%EA%B3%A0-%EA%B2%80%EC%83%89%ED%95%98%EB%8A%94-%EA%B0%80%EC%9E%A5-%ED%9A%A8%EC%9C%A8%EC%A0%81
'Machine Learning' 카테고리의 다른 글
| 머신러닝과 기존 기술 (0) | 2024.08.21 |
|---|---|
| LLM으로 문제 해결하기 (0) | 2024.08.07 |